# Librerías
library(forecast) # para predecir observaciones futuras
library(ggplot2) # Nice plots
library(readxl) # Para leer excels
library(stats) # Para crear objetos tsSeries Temporales - Holt Winters: Paro
Introducción
En este notebook se va a exponer como llevar a cabo el análisis de una serie temporal mediante un modelo Holt Winters, esto es, un suavizado exponencial triple. Para ello se verá la teoría que sustenta este método y se mostrará un caso práctico con un conjunto de datos real.
dataset
En este cuaderno vamos a analizar el dataset llamado Paro.xlsx. Este dataset presenta los datos de paro por cuatrimestre en España a partir del año 2013, posterior a la crisis económica de 2011.
Corresponde a la operación estadística del INE 30308 Encuesta de Población Activa (EPA). El objetivo de este estudio es intentar modelizar el número de parados a través de un modelo Holt-Winters y ver si realmente el número de parados se podría aproximar por este modelo sin tener en cuenta variables externas.
Parece razonable aclarar a priori el concepto de “parado” con el fin de entender que es lo que queremos modelizar. De acuerdo con el informe metodológico presentado por el INE:
Se considerarán paradas a todas las personas de 16 o más años que reúnan simultáneamente las siguientes condiciones:
estar sin trabajo, es decir, que no hayan tenido un empleo por cuenta ajena ni por cuenta propia durante la semana de referencia.
estar buscando trabajo, es decir, que hayan buscado activamente un trabajo por cuenta ajena o hayan hecho gestiones para establecerse por su cuenta durante el mes precedente.
estar disponibles para trabajar, es decir, en condiciones de comenzar a hacerlo en un plazo de dos semanas a partir del domingo de la semana de referencia.
También se consideran paradas las personas de 16 o más años que durante la semana de referencia han estado sin trabajo, disponibles para trabajar y que no buscan empleo porque ya han encontrado uno al que se incorporarán dentro de los tres meses posteriores a la dicha semana. Por lo tanto, en este caso no se exige el criterio de búsqueda efectiva de empleo.
Concretamente en este dataset tenemos las siguientes variables:
- Fecha: Fecha de medición del número de parados.
- Total: Número de parados en España en la fecha correspondiente.
Descripción del trabajo a realizar
Se pretende ajustar una serie temporal que contiene el número de parados mediante un modelo Holt Winters.
- Visualizar la serie para intuir su tendencia y estacionalidad.
- Razonar por qué es factible un modelo Holt-Winters (suavizado exponencial triple).
- Dividir la serie en Train/Test para poder evaluar después el modelo.
- Ajustar hiperparámetros e interpretar coeficientes.
Análisis Exploratorio (EDA)
EDA viene del Inglés Exploratory Data Analysis y son los pasos relativos en los que se exploran las variables para tener una idea de que forma toma el dataset.
Librerías
En este apartado se van a cargar todas las librerías necesarias para ejecutar el resto del código. Se recomienda instalarlas en caso de no disponer de ellas.
Cargamos entonces el conjunto de datos:
data <- readxl::read_excel("../../../../files/paro.xlsx",
sheet = "Datos",
col_types = c("date", "numeric")
)sum(is.na(data))[1] 0Por otra parte, para tener una noción general que nos permita describir el conjunto con el que vamos a trabajar, podemos extraer su dimensión, el tipo de variables que contiene o qué valores toma cada una.
# Dimensión del conjunto de datos
dim(data)[1] 46 2# Tipo de variables que contiene
str(data)tibble [46 × 2] (S3: tbl_df/tbl/data.frame)
$ Fecha: POSIXct[1:46], format: "2024-04-01" "2024-01-01" ...
$ Total: num [1:46] 2755 2978 2861 2894 2808 ...Suavizado exponencial: Holt Winters
El suavizado exponencial es una técnica usada para analizar y suavizar datos de series temporales. De acuerdo con este método, las observaciones pasadas tienen pesos que disminuyen exponencialmente con el tiempo.
Sea la serie temporal \(\{x_t\}\), empezando en \(t=0\). Los datos suavizados se representan como: \[ s_0 = x_0 ;\quad s_t = \alpha x_{t} + (1-\alpha)s_{t-1},\quad t>0 \] con \(\alpha\) el factor de suavizado \(0<\alpha<1\).
Concretamente vamos a tratar los siguientes tipos de suavizado, (centrándonos en el último, Holt Winters)
- Suavizado exponencial simple
- Suavizado exponencial doble (Holt-Linear)
- Suavizado exponencial triple (Holt-Winters)
Mientras que el suavizado exponencial simple se centra en suavizar la serie, el doble también intenta capturar la tendencia y el suavizado exponencial triple va un paso más allá al incorporar también la estacionalidad en los datos. Esto lo hace más adecuado para modelar series temporales con patrones estacionales claros.
Suavizado exponencial simple
La forma más simple de suavizado exponencial se da por la fórmula:
\[ s_0 = x_0 ;\quad s_t = \alpha x_{t} + (1-\alpha)s_{t-1},\quad t>0 \] con \(\alpha\) el factor de suavizado \(0<\alpha<1\).
En otras palabras, la serie suavizada es un promedio ponderado simple de la observación actual y la observación suavizada anterior.
El término “factor de suavizado” no es del todo preciso, ya que valores más grandes de \(\alpha\) reducen el nivel de suavizado, y en el caso límite con \(\alpha = 1\) la serie es simplemente la observación actual. Para valores cercanos a uno tiene menos efecto de suavizado y dan mayor peso a cambios recientes en los datos, mientras que para valores más cercanos a cero se tiene un mayor efecto de suavizado y son menos sensibles a cambios recientes.
Diferencia con medias móviles
A diferencia de otros métodos de suavizado, como el medias móviles, esta técnica no requiere que se haga un número mínimo de observaciones antes de que comience a dar la serie suavizada. Sin embargo, en la práctica, un “buen ajuste” no se logrará hasta que se hayan promediado varias muestras juntas; por ejemplo, una señal constante tomará aproximadamente \(3/\alpha\) etapas para alcanzar el \(95\%\) del valor real.
Esta forma simple de suavizado exponencial también se conoce como Exponentially Weighted Moving Average (EWMA). Técnicamente, también se puede clasificar como un modelo autoregresivo integrado de media móvil (ARIMA) (0,1,1) sin término constante.
Elección del valor de \(s_0\)
Elegir el valor inicial suavizado es crucial para una predicción precisa.
- Normalmente, el valor suavizado inicial $ s_0 $ se inicializa en $ s_0= x_0 $, la primera observación. (En caso de estacionalidad se debe elegir un valor inicial para cada periodo).
- Sin embargo, el enfoque previo puede llevar a pronósticos sesgados ya que pondera fuertemente la observación inicial. Para mitigar este problema, se recomienda usar el promedio de las observaciones durante (por ejemplo, 10 o más periodos) ese tiempo como la previsión inicial.
- Alternativamente, se pueden usar otros métodos para establecer el valor inicial, pero es importante tener en cuenta que la elección se vuelve más crítica con valores más pequeños del parámetro de suavizado $ $, ya que el pronóstico se vuelve más sensible al valor inicial suavizado.
Optimización (hiperparámeteros)
De esta manera tenemos el siguiente hiperparámetro denominándose : - \(\alpha\): factor de suavizado de la serie
Los parámetros desconocidos y los valores iniciales para cualquier método de suavizado exponencial pueden estimarse minimizando la suma de errores al cuadrado (SSE). Los errores se especifican como \(e_t=y_t-\hat{y}_{t\mid t-1}\) y lo que se busca es minimizar \(SSE=\sum e_t^2\).
A diferencia del caso de regresión (donde tenemos fórmulas para calcular directamente los coeficientes de regresión que minimizan el SSE), esto implica un problema de minimización no lineal y necesitamos utilizar una herramienta de optimización para realizarlo.”
Comparación con Medias Móviles
- Ambos tienen aproximadamente la misma distribución de error de pronóstico cuando \(\alpha = 2/(k + 1)\).
- Difieren en que el suavizado exponencial tiene en cuenta todos las observaciones pasados, mientras que las ** medias móviles** solo tiene en cuenta k observaciones pasadas.
- Computacionalmente hablando, también difieren en que el método de medias móviles requiere que se conserven las últimas \(k\) observaciones de datos, mientras que el suavizado exponencial solo necesita conservar el valor suavizado para el \(t\) más reciente.
Suavizado exponencial doble (Holt linear)
- El suavizado exponencial simple no funciona bien cuando hay una tendencia en los datos.
- En esos casos se usa el “suavizado exponencial doble” o “suavizado exponencial de segundo orden”, que es la aplicación recursiva de un filtro exponencial dos veces.
- La idea básica es introducir un término para tener en cuenta la posibilidad de que una serie muestre alguna forma de tendencia. Esta componente se actualiza mediante suavizado exponencial.
No se expondrán las fórmulas por simplicidad pero adicionalmente hay que ajustar otro hiperparámetro \(\beta\). De esta manera tenemos los siguientes hiperparámetros principales denominándose :
- $\alpha$: factor de suavizado de la serie
- $\beta$: factor de suavizado de tendencia
- $\gamma$: factor de suavizado de tendenciaSuavizado exponencial triple (Holt-Winters)
El suavizado exponencial triple aplica el suavizado exponencial tres veces. Fue sugerido por primera vez por el estudiante de Holt, Peter Winters, en 1960 después de leer un libro de procesamiento de señales de la década de 1940 sobre suavizado exponencial. Además de suavizar la serie y la tendencia, también considera la estacionalidad en los datos. (el suavizado doble no considera directamente la estacionalidad en los datos.)
De esta manera tenemos los siguientes hiperparámetros principales denominándose:
- $\alpha$: factor de suavizado de la serie
- $\beta$: factor de suavizado de tendencia
- $\gamma$: modelado de la estacionalidadDestacar que hay diferentes tipos de estacionalidad: multiplicativa y aditiva en la naturaleza, al igual que la suma y la multiplicación son operaciones básicas en matemáticas.
- Si cada mes de diciembre vendemos 10,000 apartamentos más que en noviembre, la estacionalidad es de naturaleza aditiva. -Sin embargo, si vendemos un 10% más de apartamentos en los meses de verano que en los meses de invierno, la estacionalidad es de naturaleza multiplicativa. La estacionalidad multiplicativa puede representarse como un factor constante, no como una cantidad absoluta.
Vamos a cargar los datos en un objeto adecuado para su análisis.
# Convertir el vector en una serie temporal
tss <- ts(rev(data$Total), start = 2013, frequency = 4)
# creamos train/test partición
data.train <- window(tss, end = c(2022, 4))
data.test <- window(tss, start = c(2023, 1))# resumen numérico
summary(data.train) Min. 1st Qu. Median Mean 3rd Qu. Max.
2995 3323 3749 4193 4925 6278 # Visualizamos la serie
plot(data.train, main = "Paro cuatrimestral", xaxt = "n")
axis(1, at = seq(2013, 2023, 1)) # X-axis mostrar cada 2 años
legend("topright", legend = c("Paro"), col = "black", lty = 1)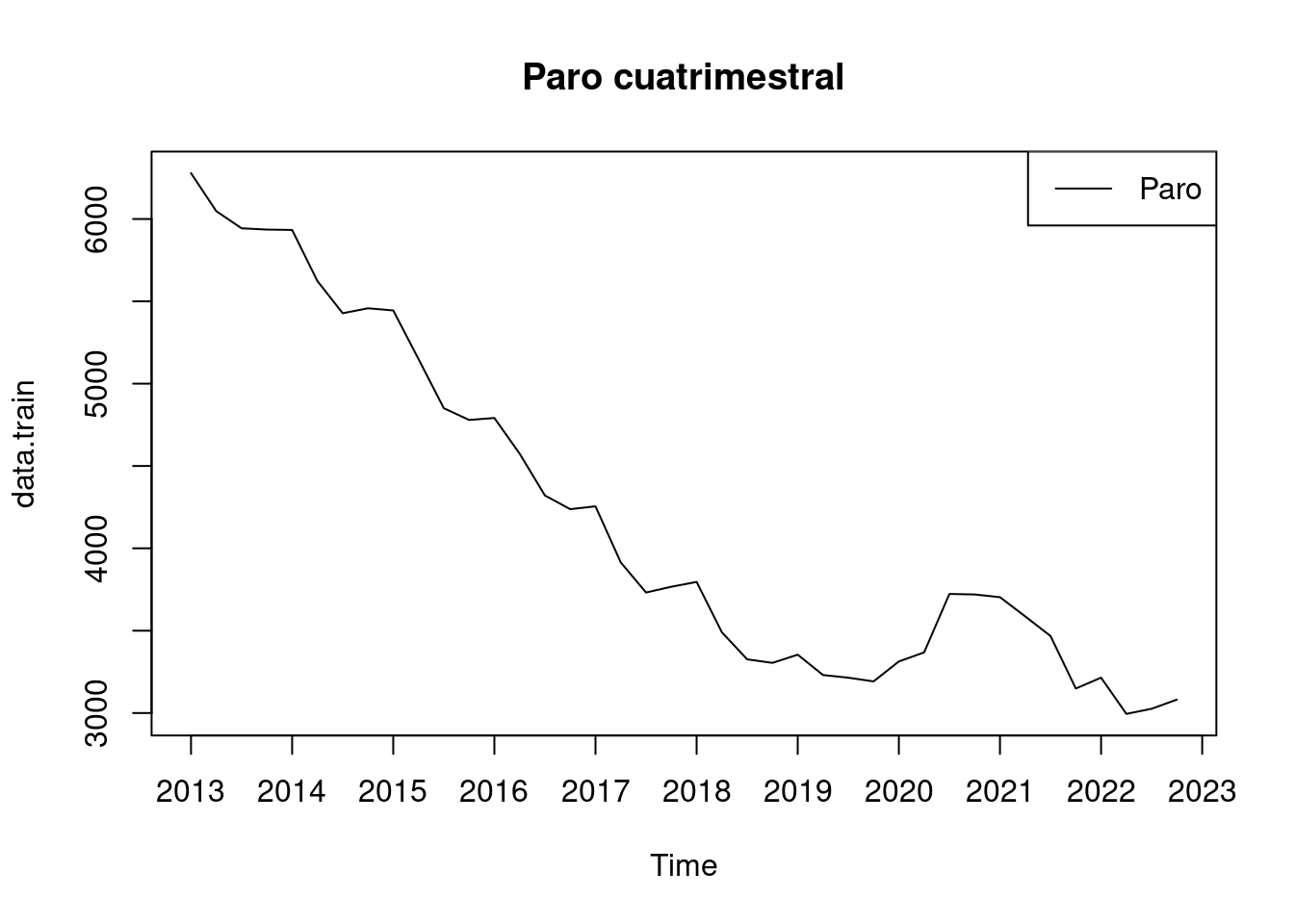
A primera vista ya se parece ver que la serie tiene una componente estacional puesto que hay picos de alta frecuencia dentro del año. Además se observa una tendencia decreciente a lo largo de los años. Es por ello que el método de Holt-Winters parece adecuado. Por la misma razón se ve desaconsejable usar un suavizado exponencial simple o doble.
Es por ello que ejecutamos el modelo inicial, dejando al algoritmo que busque los valores óptimos de los hiperparámetros.
# Modelo inicial
mod1 <- HoltWinters(data.train, seasonal = "additive")
# Visualizamos serie y serie ajustada por modelo
plot(mod1, xaxt = "n")
legend("topright", legend = c("Original", "Holt Winters"), col = c("black", "red"), lty = 1)
# X-axis mostrar cada 2 años
axis(1, at = seq(2013, 2028, 1))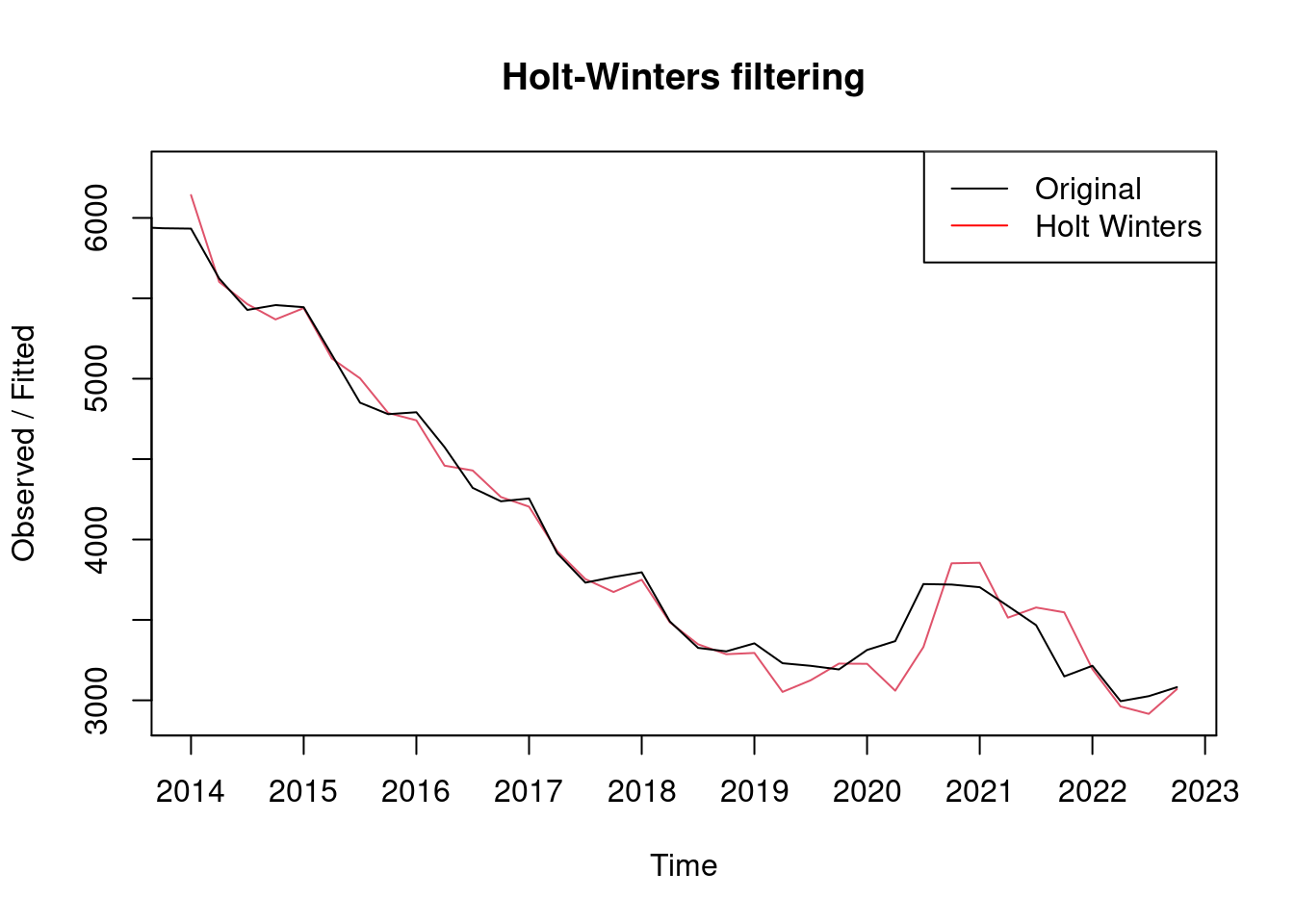
Se puede observar que R a través del comando HoltWinters crea una gráfica en color rojo, en donde se crean una nueva serie de datos que en teoría están muy cerca de los datos originales que son los de color negro. Es por ello que a priori el ajuste parece bueno. No obstante, se deben hacer las comprobaciones pertinentes.
mod1Holt-Winters exponential smoothing with trend and additive seasonal component.
Call:
HoltWinters(x = data.train, seasonal = "additive")
Smoothing parameters:
alpha: 1
beta : 0.1537324
gamma: 1
Coefficients:
[,1]
a 3070.56562
b -42.91375
s1 126.24687
s2 -59.95312
s3 -77.32812
s4 11.03438Esta salida corresponde a un modelo de suavizado exponencial de Holt-Winters con tendencia y componente estacional aditiva.
- Parámetros de Suavizado:
- alpha: El parámetro de suavizado para la nivel base es aproximadamente 1. Indica cuánto peso se le da a las observaciones más recientes para calcular el nivel base.
- beta: El parámetro de suavizado para la tendencia es 0.15, lo que sugiere que se está considerando muy levemente el suavizado para la tendencia en este modelo.
- gamma: El parámetro de suavizado para la componente estacional es 1, lo que indica un fuerte énfasis en la suavización de la componente estacional.
- Coeficientes:
- a: El nivel base es aproximadamente 3.070 (miles) de parados Representa el valor promedio de la serie temporal.
- b: La pendiente de la tendencia es alrededor de -42. Indica la tasa de cambio en la serie temporal.
- s1 a s4: Estos coeficientes representan los efectos estacionales para cada uno de los 4 trimestres del año. Los valores negativos indican una contribución negativa a la estacionalidad, mientras que los valores positivos indican una contribución positiva. Por ejemplo, los coeficientes positivos para s1 y s4 sugieren un aumento estacional durante esos meses.
mod1 <- HoltWinters(data.train)
mod1Holt-Winters exponential smoothing with trend and additive seasonal component.
Call:
HoltWinters(x = data.train)
Smoothing parameters:
alpha: 1
beta : 0.1537324
gamma: 1
Coefficients:
[,1]
a 3070.56562
b -42.91375
s1 126.24687
s2 -59.95312
s3 -77.32812
s4 11.03438checkresiduals(mod1)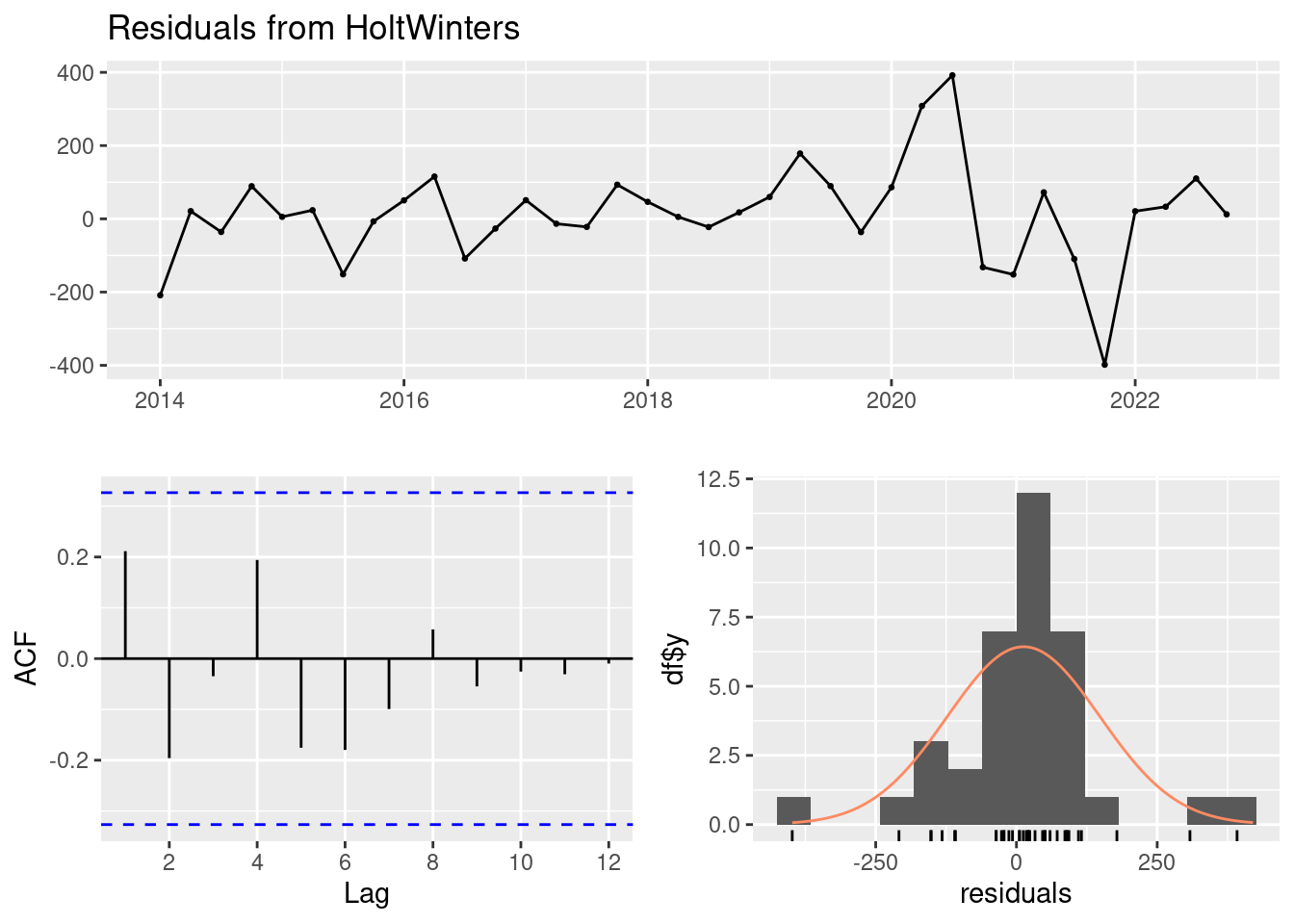
Ljung-Box test
data: Residuals from HoltWinters
Q* = 8.2535, df = 7, p-value = 0.3108
Model df: 0. Total lags used: 7RESIDUOS
Veamos que tal ha ajustado el modelo la serie (examinando los residuos):
checkresiduals(mod1)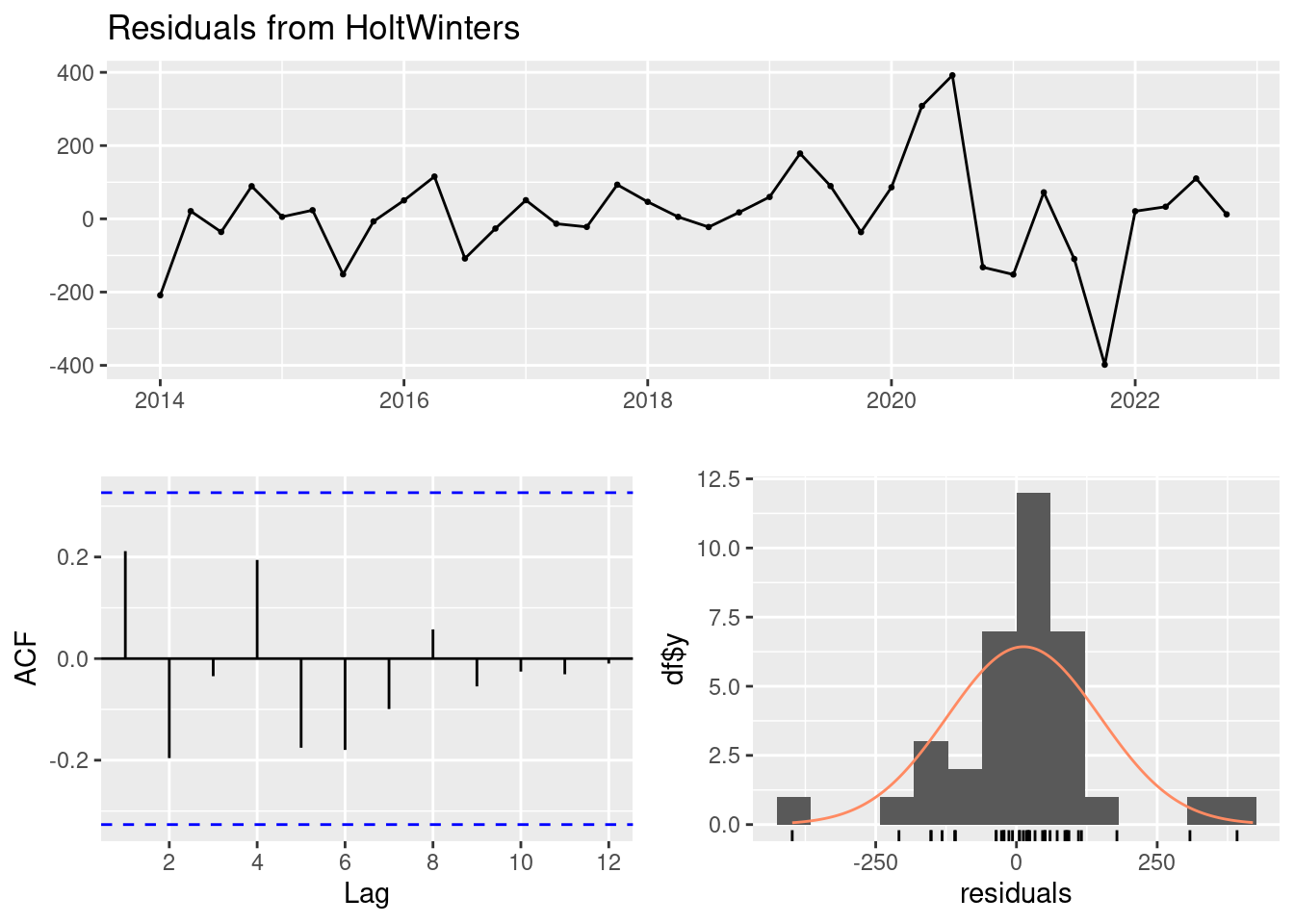
Ljung-Box test
data: Residuals from HoltWinters
Q* = 8.2535, df = 7, p-value = 0.3108
Model df: 0. Total lags used: 7El test de Ljung-Box en los residuos del modelo no son significativamente diferentes de un ruido blanco (dado que el valor p es 0.3108, que es mayor que 0.05). Esto implica que el modelo está capturando adecuadamente los patrones en los datos de desempleo y que los residuos son aleatorios.
- El Ljung-Box test tiene un p_val<0.05 luego no podemos aceptar H0 y asumir que los errores son independientes.
- Gráfico Residuos vs. Índice: Este gráfico muestra los residuos en función del índice de las observaciones. Idealmente, los residuos deberían estar dispersos alrededor de cero sin ningún patrón discernible (parece que no lo están del todo).
- Gráfico Autocorrelación de Residuos: muestra la autocorrelación de los residuos a diferentes rezagos. Se espera que los residuos no estén correlacionados entre sí, lo que se reflejaría en que los puntos estén dentro de las bandas de confianza. Se pasa la prueba.
- Histograma de Residuos: Muestra la distribución de los residuos. Si los residuos se distribuyen normalmente alrededor de cero, el histograma debería parecerse a una distribución normal. (podría considerarse aceptable)
Esto significa que no hay evidencia significativa de autocorrelación en los residuos, sugiriendo que el modelo es adecuado.
Predicción Adicionalmente, se va a llevar a cabo una predicción sobre las observaciones sustraídas y se va a comparar con los valores reales a ver que efectividad tiene. Concretamente se va a hacer para los 6 meses posteriores. Comentar que cuanto más grande sea el test data, peor serán las métricas de la predicción, puesto que es muy difícil predecir en un periodo alejado del tiempo.
Vamos a mostrar ahora:
- ME: Mean Error
- RMSE: Root Mean Squared Error
- MAE**: Mean Absolute Error
- MPE: Mean Percentage Error
- MAPE: Mean Absolute Percentage Error
- MASE: Mean Absolute Scaled Error
- ACF1: Autocorrelation of errors at lag 1.
# Predecir los 7 meses siguientes
data.f1 <- forecast(mod1, h = 6)
# check accuracy
accuracy(data.f1, data.test) ME RMSE MAE MPE MAPE MASE
Training set 12.68438 134.47703 91.80854 0.4192598 2.463449 0.21388543
Test set -17.58313 54.74325 39.10813 -0.6471846 1.357927 0.09110981
ACF1 Theil's U
Training set 0.2115799 NA
Test set -0.7018512 0.2788822En el conjunto de datos de test vemos que el MPE y el MAPE muestran alrededor de un 1.3% lo cual es buen indicador. Podemos repetir el estudio con ARIMA para ver si obtenemos cosas coherentes, ya que hemos visto que algunas hipótesis de los residuos no se cumplían en este modelo.
NOTA IMPORTANTE: No siempre es importante que la serie prediga bien los valores. Por ejemplo, una empresa dedicada a la compra de petróleo en crudo puede estar más interesada en saber si la tendencia los meses siguientes será decreciente/creciente, para saber si la actualidad es buen momento para comprar petróleo. Es por ello que los análisis se centran más en contrastes de hipótesis.
Hyperparameter tunning
Aunque en este notebook en la función Holt.Wintersse han dejado los parámetros alpha, betay gamma autoajustarse, un enfoque alternativo podría ser establecer una rejilla de valores creando diferentes modelos con diferentes valores y comparando el MPE y el MAPE para ver que modelo tiene mejores métricas. Se tomarían como adecuados los parámetros del modelo con mejores métricas.
Veamos un ejemplo, vamos a buscar el gamma óptimo.
# Rejilla de gammas
gamma <- seq(0.1, 0.9, 0.05)
# Inicializamos
RMSE <- NA
# Bucle que analiza los modelos con todos los gammas propuestos (autoajustando el resto de hiperparámetros)
for (i in seq_along(gamma)) {
mod1.bucle <- HoltWinters(data.train, gamma = gamma[i], seasonal = "additive")
future <- forecast(mod1.bucle, h = 5)
RMSE[i] <- accuracy(future, data.test)[2, 4]
}
# Copiamos el RMSE de todos
error <- data.frame(gamma, RMSE)
# Buscamos el mínimo
minimum <- error[which(error$RMSE == min(error$RMSE)), ]
ggplot(error, aes(gamma, RMSE)) +
geom_line() +
geom_point(data = minimum, color = "blue", size = 2) +
ggtitle("gamma's impact on forecast errors",
subtitle = "gamma = 0.65 minimizes RMSE"
)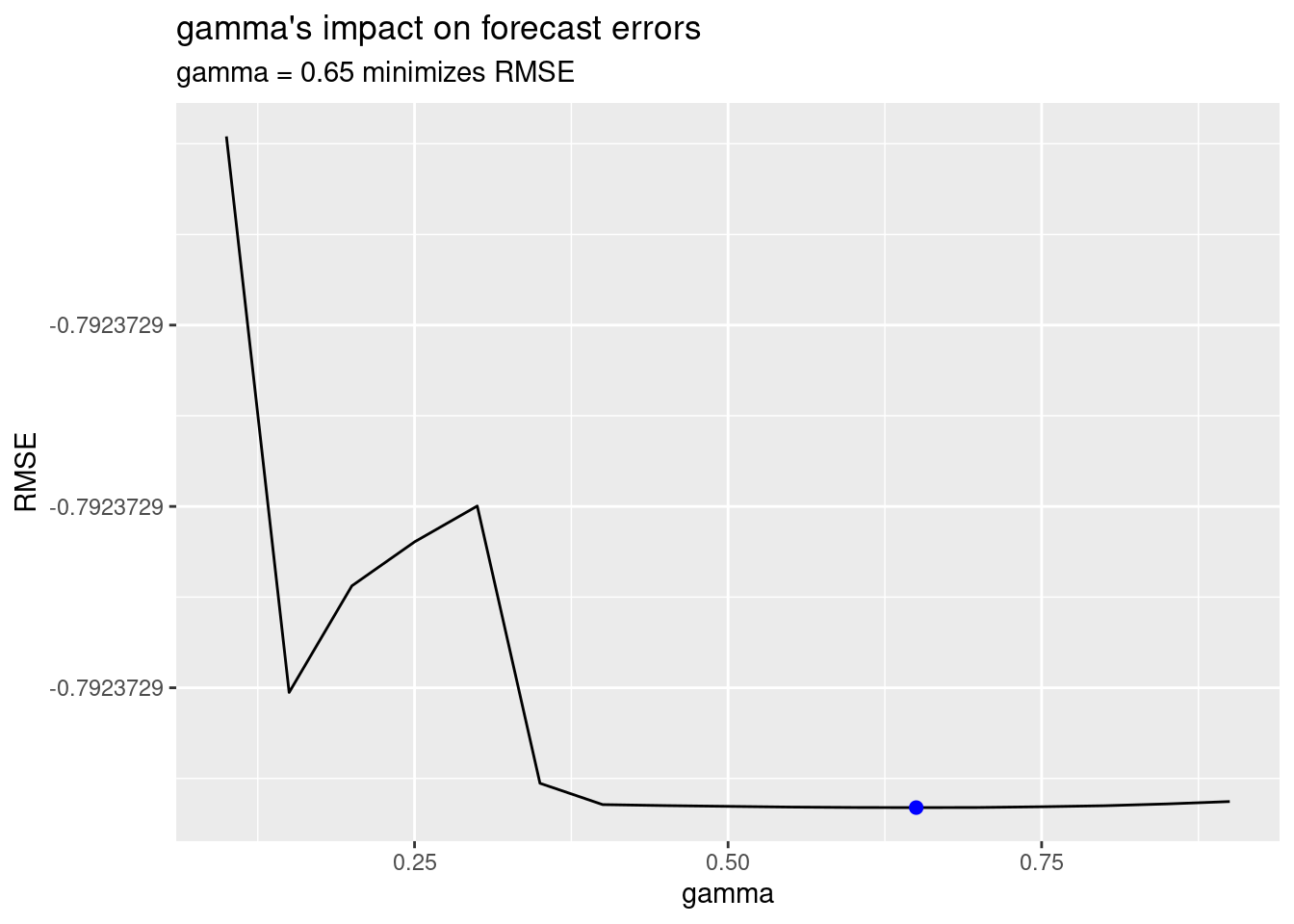
Si actualizamos nuestro modelo con este parámetro “óptimo” de gamma, observamos que el MAPE se queda parecido. Esto representa una mejora pequeña, pero a menudo las mejoras pequeñas pueden tener grandes implicaciones comerciales.
Veamos concretamente las métricas:
mod1.bucle <- HoltWinters(data.train, gamma = 0.65, seasonal = "additive")
future <- forecast(mod1.bucle, h = 6)
accuracy(future, data.test) ME RMSE MAE MPE MAPE MASE
Training set 12.68438 134.47703 91.80854 0.4192598 2.463449 0.21388543
Test set -17.58313 54.74325 39.10813 -0.6471846 1.357927 0.09110981
ACF1 Theil's U
Training set 0.2115799 NA
Test set -0.7018512 0.2788822checkresiduals(mod1.bucle)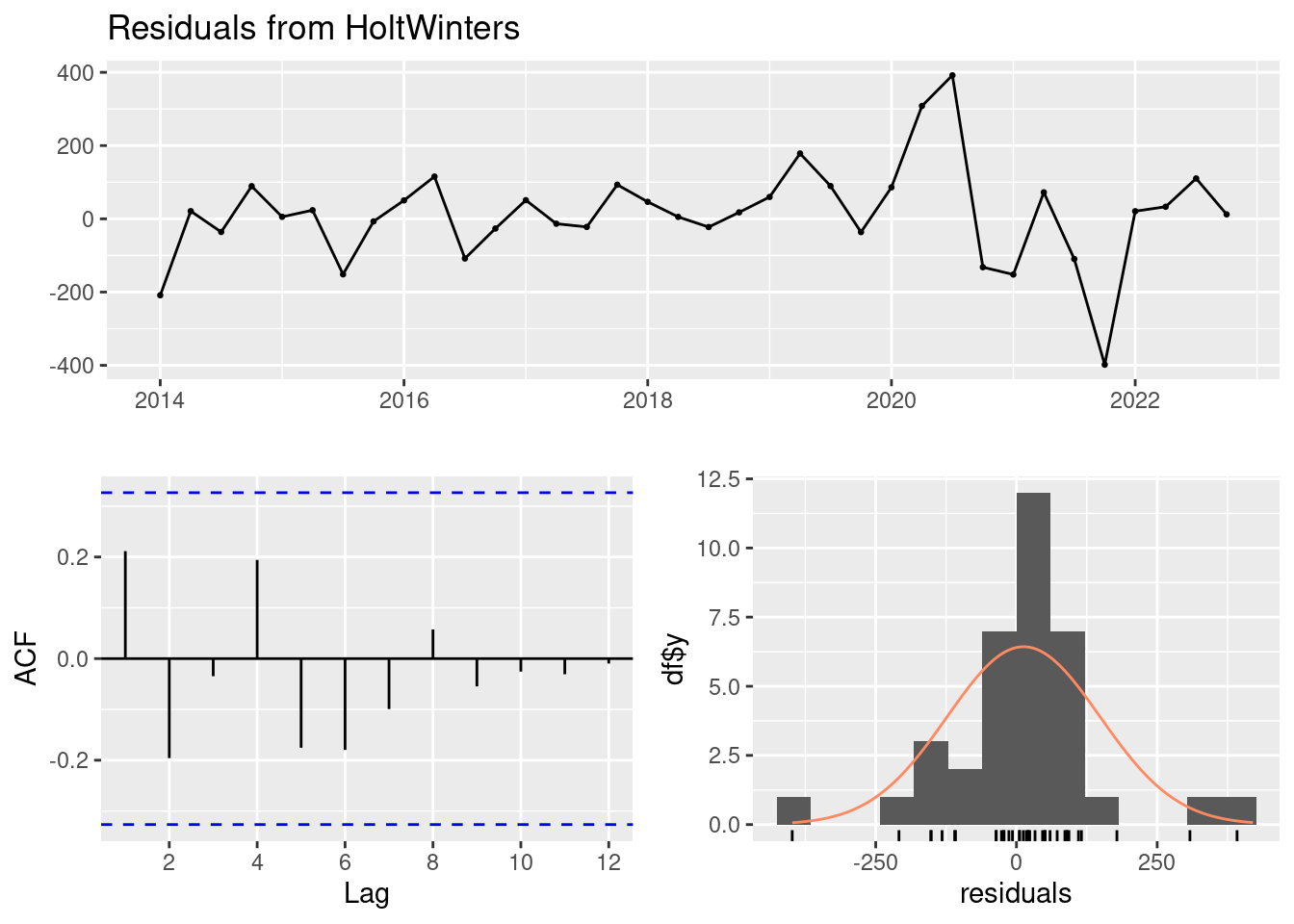
Ljung-Box test
data: Residuals from HoltWinters
Q* = 8.2535, df = 7, p-value = 0.3108
Model df: 0. Total lags used: 7Vamos a graficarlo a ver que las predicciones futuras:
autoplot(future)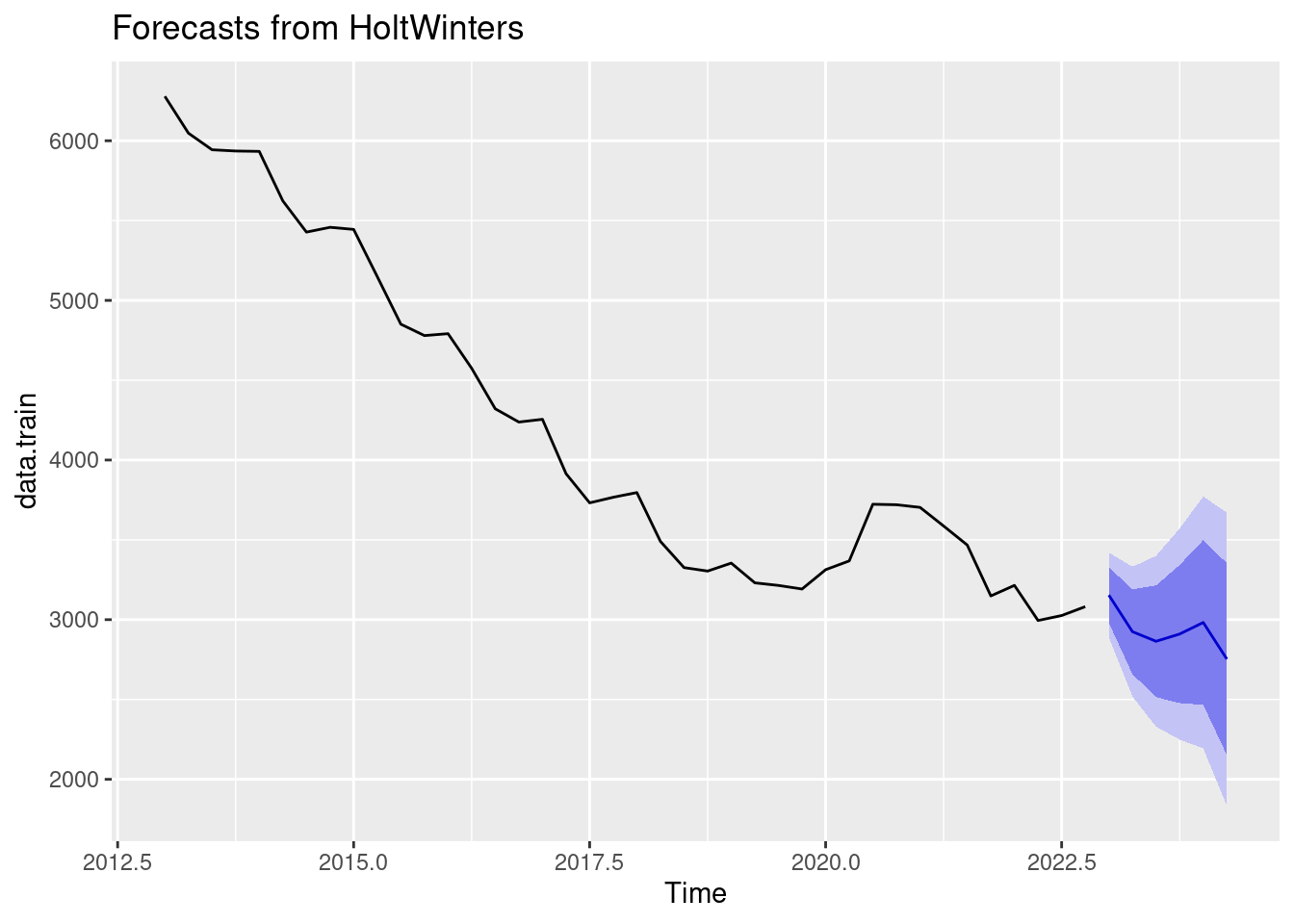
Conclusión
En este notebook se ha explorado como llevar a cabo un Análisis de una serie temporal mediante un modelo de Holt Winters, las hipótesis que debe cumplir el ajuste para considerarlo como bueno y los aspectos a tener en cuenta durante el proceso de modelización. Además se ha puesto en evidencia como no siempre es posible satisfacer todas necesidades del modelo.