library(readxl) # Para leer los excels
# library(kableExtra) # Para dar formato a las tablas html
library(knitr)
library(gridExtra) # Para cargar bien las tab
library(car) # for bonfferroni test
library(ggplot2)Regresión Lineal: salud_reg
Introducción
En este notebook se expondrá como llevar a cabo una Regresión Lineal a partir de un conjunto de datos, explicando las hipótesis que se deben satisfacer y un posterior análisis de bondad del modelo. Por último se explicará como utilizar el modelo creado para predecir nuevas observaciones.
dataset
En este cuaderno vamos a analizar el dataset llamado salud_reg.xlsx. Este contiene microdatos relativos a la Encuesta Nacional de Salud a personas en 2017. Altura, Peso, Edad, Sexo e IMC del encuestado con el fin de hacer una regresión del Peso en función del resto de variables y explicar por qué es interesante este estudio.
Concretamente tenemos las siguientes variables:
Edad: Edad en años cumplidos del encuestado.
Sexo : Sexo del encuestado (1=Hombre, 0=Mujer).
Altura : Edad en cm del encuestado.
Peso : Peso en kg del encuestado.
IMC : “Clasificación del IMC de la persona.
- 1: Peso insuficiente
- 2: Normopeso
- 3: Sobrepeso
- 4: Obesidad
Nota: Notar que el Índice de Masa Corporal (IMC) es un indicador que pone en relación el peso (en kg) de la persona, con su altura en metros (al cuadrado). Informalmente, esta medida se toma como un indicador básico del estado de salud de la persona.
Si conociéramos el IMC exacto, no tendría sentido efectuar el Análisis de Regresión puesto que el Peso se podría calcular directamente despejando IMC y Altura. Sin embargo, tenemos categorías para el IMC, que son: Peso Insuficiente, Normal, Sobrepeso y Obesidad. Bajo este paradigma tiene sentido plantear la regresión para ver si somos capaces de recuperar el Peso de una persona, sin conocer directamente su IMC, sino la clase en la que cae, junto con su Altura. Además se verá si el resto de variables ayudan a estimar el Peso.
Descripción del trabajo a realizar
Elaborar una Regresión Lineal que explique el Peso en función del resto de las variables.
- Hacer un análisis exploratorio.
- Plantear las hipótesis de una regresión (incluyendo todas variables).
- Analizar el modelo planteado y su ajuste de bondad.
- Evaluar distintos modelos y seleccionar el más adecuado.
- Conclusión.
Análisis Exploratorio (EDA)
EDA viene del Inglés Exploratory Data Analysis y son los pasos relativos en los que se exploran las variables para tener una idea de que forma toma el dataset.
Cargar Librerías
Lo primero de todo vamos a cargar las librerías necesarias para ejecutar el resto del código del trabajo:
Lectura datos
Ahora cargamos los datos del excel correspondientes a la pestaña “Datos” y vemos si hay algún NA o algún valor igual a 0 en nuestro dataset. Vemos que no han ningún NA (missing value) en el dataset luego no será necesario realizar ninguna técnica para imputar los missing values o borrar observaciones.
salud <- read_excel("../../../files/salud_reg.xlsx", sheet = "Datos")anyNA(salud) # Any missing data[1] FALSEAnálisis
Realizando un resumen numérico vemos que:
summary(salud) EDAD SEXO Altura Peso
Min. : 15.00 Length:22019 Min. :120.0 Min. : 26.00
1st Qu.: 39.00 Class :character 1st Qu.:160.0 1st Qu.: 62.00
Median : 52.00 Mode :character Median :166.0 Median : 71.00
Mean : 52.84 Mean :166.7 Mean : 72.66
3rd Qu.: 67.00 3rd Qu.:173.0 3rd Qu.: 81.00
Max. :103.00 Max. :204.0 Max. :180.00
IMC
Length:22019
Class :character
Mode :character
table(salud$SEXO)
0 1
11701 10318 table(salud$IMC)
1 2 3 4
475 9301 8333 3910 Resumen de la variable EDAD:
La edad varía entre 15 y 103 años.
La mediana (50º percentil) de la edad es 52 años.
La media de la edad es aproximadamente 52.84 años.
El rango intercuartílico (IQR) de la edad va desde el primer cuartil (Q1) a Q3 (39 a 67 años).
Tabla de frecuencia para la variable SEXO:
Hay dos categorías de sexo representadas como “0” y “1”.
Hay 11,701 individuos clasificados como “0” ( mujeres).
Hay 10,318 individuos clasificados como “1” ( hombres).
Tabla de frecuencia para la variable IMC: Hay cuatro categorías de índice de masa corporal (IMC) representadas como “1”, “2”, “3” y “4”. - La frecuencia de la categoría “1” es 475. - La frecuencia de la categoría “2” es 9,301. - La frecuencia de la categoría “3” es 8,333. - La frecuencia de la categoría “4” es 3,910.
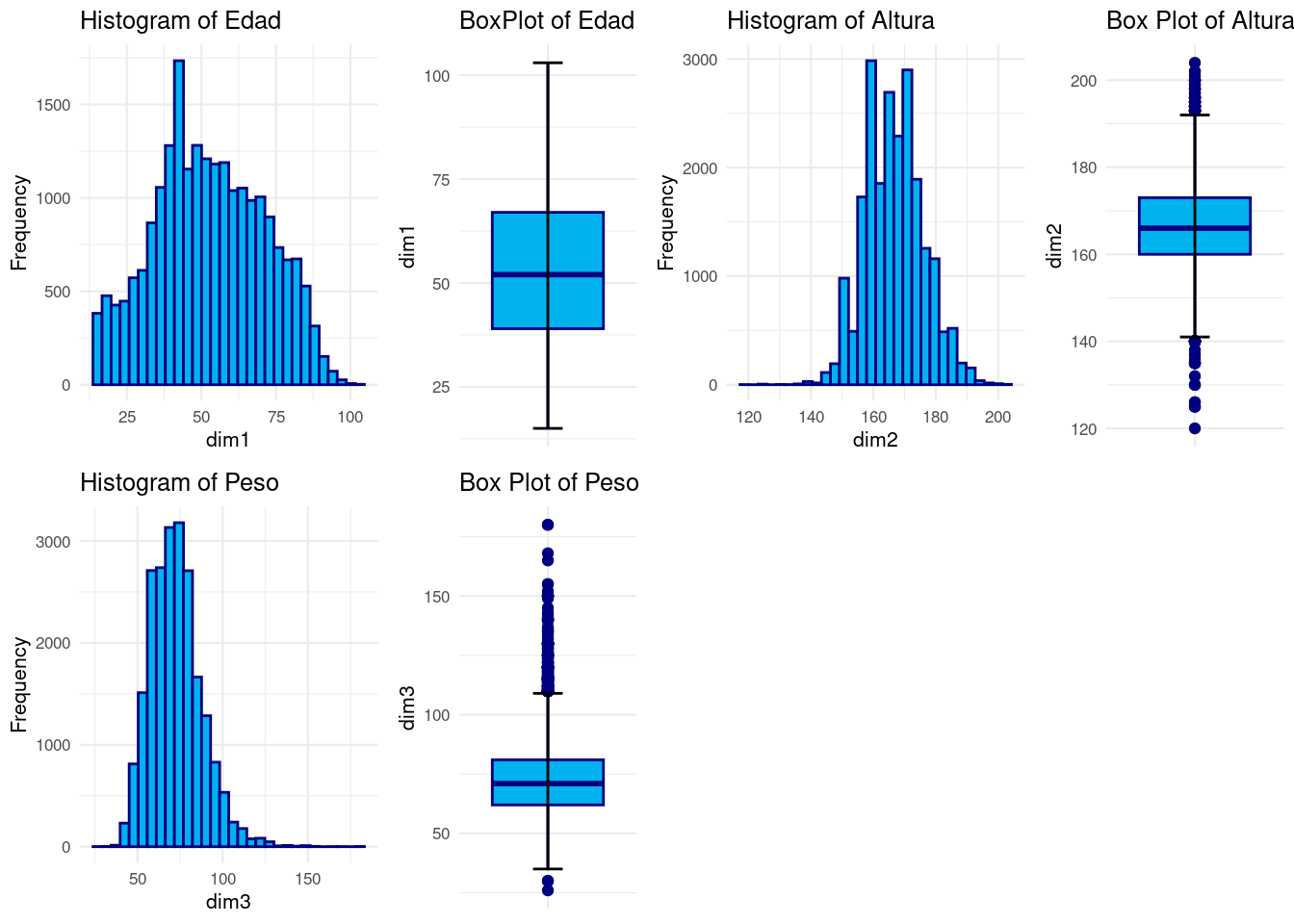
[1] 812En los histogramas vemos la forma de cada distribución las cuales parecen razonables con la idea que podemos tener preconcebida acerca de dichas variables.
- En la gráfica de la altura se observamos que es bastante más simétrica que el peso, que presenta asimetría positiva. Esto se puede deber a que sobre nuestra altura nosotros no jugamos ningún papel directo, suele venir influencia por la genética y factores fuera del alcance de nuestra mano, de ahí que sea muy simétrica.
- Sin embargo, el peso es muy fácil aumentarlo/disminuirlo. Generalmente en una sociedad desatollada es normal tener más facilidad para comer por exceso que por deceso, luego parece razonable que esté sesgada hacia la derecha.
Regresión Lineal
Una Regresión Lineal es una técnica estadística que busca ajustar un conjunto de datos a una recta. Es decir, dada una observación x, se proyecta sobre la recta y se obtiene un valor y, de tal manera que si el ajuste por regresión es bueno entonces la \(\hat{y}\) obtenida se parece mucho al valor real \(y\).
Antes de explicar las hipótesis que deben cumplir los datos para que el ajuste y como llevarlo a cabo, se va a mostrar un ejemplo de buen y mal ajuste. Intuitivamente cuanto mejor sea el ajuste de los datos a una recta cuando se representen las observaciones en un gráfico, mejor será el ajuste.
par(mfrow = c(1, 2)) # Dos gráficos misma fila
# Poca variabilidad
x <- seq(1, 100, 1)
y <- rnorm(100, x, 5)
p1 <- plot(y, col = "lightblue", main = "BUEN Ajuste") + abline(lm(y ~ x), col = "navy")
# Mucha variabilidad
x_malo <- seq(1, 100, 1)
y_malo <- rnorm(100, x, 35)
p2 <- plot(y_malo, col = "lightblue", main = "MAL Ajuste") + abline(lm(y_malo ~ x_malo), col = "navy")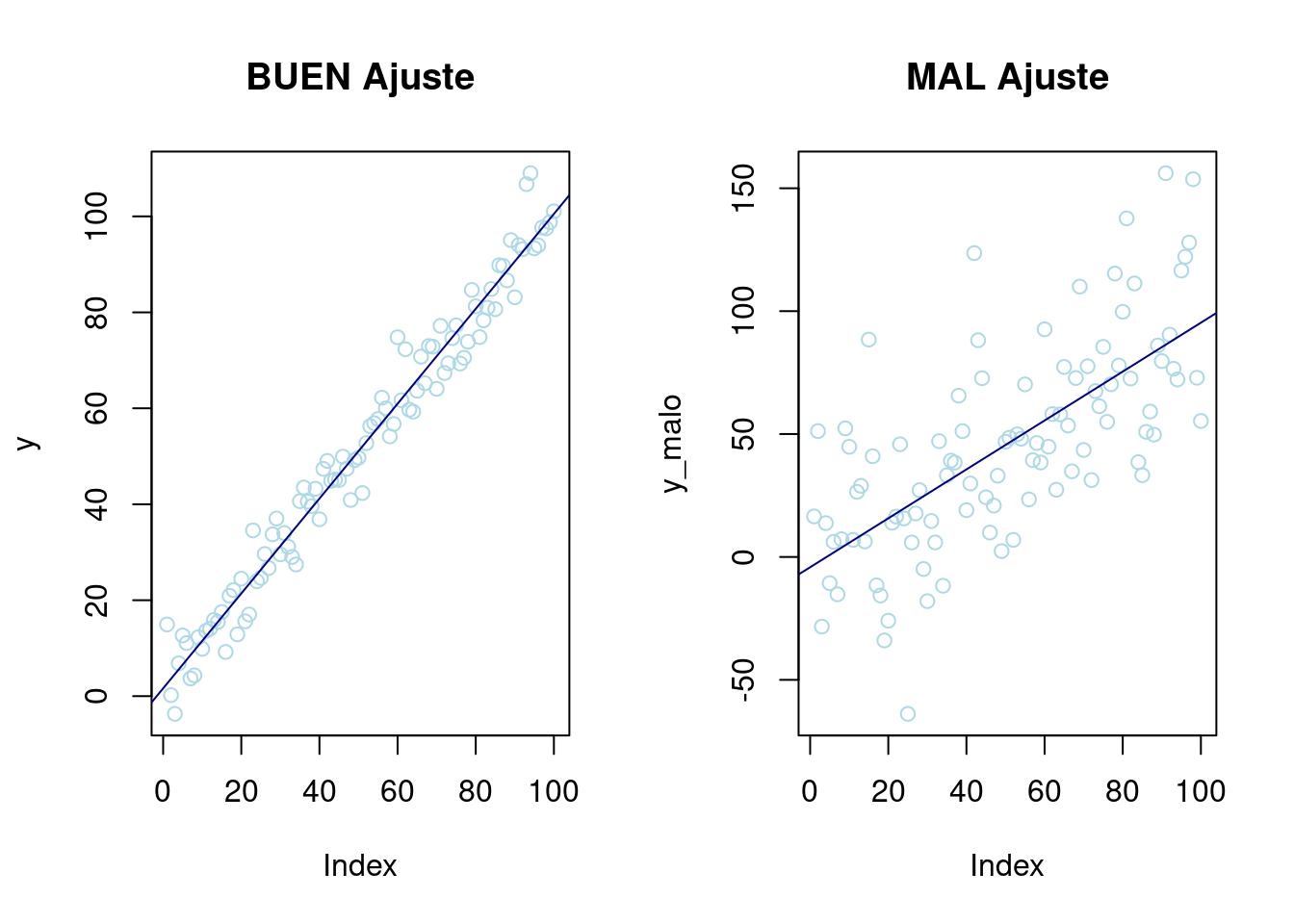
Hipótesis y indicadores de bondad
Para que una regresión lineal proporcione un buen ajuste a los datos debe cumplir una serie de requisitos que por tanto deben ser verificados al llevar a cabo el estudio. Recordar que la regresión lineal se expresa como:
\[ \mathbf{Y}=\mathbf{X} \boldsymbol{\beta}+\boldsymbol{\varepsilon} \] donde \(\mathbf{Y}\) es la variable respuesta, \(\mathbf{X}\) los predictores (hay \(k\) variables predictoras), \(\boldsymbol{\beta}\) los coeficientes de la regresión y \(\boldsymbol{\varepsilon}\) el error. \[ \mathbf{Y}=\left[\begin{array}{c} y_1 \\ y_2 \\ \vdots \\ y_n \end{array}\right] \quad \mathbf{X}=\left[\begin{array}{cccc} 1 & x_{11} & \ldots & x_{1 k} \\ 1 & x_{21} & \ldots & x_{2 k} \\ \vdots & \ddots & \vdots & \\ 1 & x_{n 1} & \ldots & x_{n k} \end{array}\right] \quad \boldsymbol{\beta}=\left[\begin{array}{c} \beta_0 \\ \beta_1 \\ \vdots \\ \beta_k \end{array}\right] \quad \boldsymbol{\varepsilon}=\left[\begin{array}{c} \varepsilon_1 \\ \varepsilon_2 \\ \vdots \\ \varepsilon_n \end{array}\right] \] Las hipótesis que se deben cumplir son:
Linealidad: La media de la respuesta es función lineal de los predictores. En términos matemáticos: \[E\left[\mathbf{Y} \mid \mathbf{X}_1=x_1, \ldots, \mathbf{X}_k=x_k\right]=\beta_0+\beta_1 x_1+\ldots+\beta_k x_k \]
Independencia de errores: Los errores \(\varepsilon_i\) deben ser independientes, es decir, \(Cov[\varepsilon_i,\varepsilon_j] =0, \; \forall i\neq j\).
Homocedasticidad: La varianza del error debe ser constante.
\[Var\left[\varepsilon_i \mid \mathbf{X}_1=x_1, \ldots, \mathbf{X}_k=x_k\right]=\sigma^2 \quad \forall \;i \]
- Normalidad : Los errores deben estar distribuidos normalmente, es decir, \(\varepsilon_i \sim N(0,\sigma^2)\; \forall i\).
Para analizar la bondad, hay algunos indicadores como el Coeficiente de Determinación o \(R^2\) que representa el porcentaje de variabilidad de la variable respuesta que es capaz de explicar el modelo. Es decir, si toma valor 1 hay una dependencia lineal exacta entre los predictores y la variable respuesta y por tanto las predicciones serán perfectas. Por el contrario, si toma valor 0 habrá que desechar el modelo puesto que no es capaz de predecir con nada de exactitud.
En caso de que haya más de un predictor (\(k >1\), Regresión Lineal Múltiple), es más recomendable usar el Coeficiente de Determinación Ajustado \(R^2\_adj\) como indicador de bondad, pues el \(R^2\) puede inflarse artificialmente debido a la presencia de varios predictores. Su interpretación es similar.
Modelo
En este caso nos encontramos ante una Regresión Lineal Múltiple puesto que tenemos más de una variable predictora. Inicialmente vamos a considerar un modelo con todas variables predictoras para intentar predecir el \(peso\) y veremos si este modelo cumple las hipótesis necesarias y cuan bueno es.
NOTA IMPORTANTE: Destacar que hay predictores que son variables discretas (no continuas), luego se deberán tratar como variables factor en R. En este notebook se verá como interpretar los resultados cuando están presentes este tipo de variables. La principal diferencia es que los modelos de regresión usan internamente variables dummy para este tipo de variables, luego por cada variable factor habrá tantos coeficientes de regresión como categorías menos uno, es decir, como número de variables dummy. Este tipo de codificación se denomina One Hot Encoding, para más información leer el link.
# Convertir a factor variables
salud$SEXO <- as.factor(salud$SEXO)
salud$IMC <- as.factor(salud$IMC)
# Dividimos los datos en Train/Test
salud_test <- salud[22000:22019, ]
salud <- salud[1:21999, ]
# Modelo inicial
lm1 <- lm(Peso ~ EDAD + Altura + IMC + SEXO, salud)
summary(lm1)
Call:
lm(formula = Peso ~ EDAD + Altura + IMC + SEXO, data = salud)
Residuals:
Min 1Q Median 3Q Max
-16.946 -3.845 -0.137 3.510 79.105
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) -94.986808 1.027145 -92.477 <2e-16 ***
EDAD 0.027838 0.002288 12.169 <2e-16 ***
Altura 0.854409 0.005848 146.115 <2e-16 ***
IMC2 13.430315 0.270893 49.578 <2e-16 ***
IMC3 26.165755 0.274741 95.238 <2e-16 ***
IMC4 43.391437 0.282888 153.387 <2e-16 ***
SEXO1 1.000631 0.106538 9.392 <2e-16 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 5.735 on 21992 degrees of freedom
Multiple R-squared: 0.852, Adjusted R-squared: 0.852
F-statistic: 2.11e+04 on 6 and 21992 DF, p-value: < 2.2e-16A primera vista vemos un valor de Múltiple R-squared: 0.8521,, lo cual es bastante alto y por tanto nuestro modelo parece capturar bien la variabilidad de la variable respuesta, concretamente un \(85\%\). Sin embargo, en los sucesivos modelos que plantemos no podemos usar como criterio de comparación el \(R-squared\) pues aumenta a la vez que lo hace el número de variables, y por tanto para comparar modelos entre si se debe usar el Adjusted R-squared (que tiene en cuenta el número de variables).
En la línea de los residuos no parece haber contraindicaciones a que estos sigan una distribución normal centrada en cero puesto que tenemos unas medidas de dispersión bastante simétricas. No obstante, más adelante se procederán a hacer los test pertinentes.
Ahora vamos a reducir el número de predictores que incluimos en el modelo y analizaremos que impacto tiene esto en la bondad.
- En el modelo lm2, quitamos en primer lugar la variable Sexo, dejando EDAD, Altura, IMC.
- En el modelo lm3, quitamos en primer lugar la variable IMC, dejando EDAD, Altura.
# Sin Sexo
lm2 <- lm(Peso ~ EDAD + Altura + IMC, salud)
summary(lm2)
Call:
lm(formula = Peso ~ EDAD + Altura + IMC, data = salud)
Residuals:
Min 1Q Median 3Q Max
-16.897 -3.891 -0.126 3.543 79.268
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) -1.010e+02 8.017e-01 -126.03 <2e-16 ***
EDAD 3.109e-02 2.266e-03 13.72 <2e-16 ***
Altura 8.912e-01 4.352e-03 204.79 <2e-16 ***
IMC2 1.358e+01 2.710e-01 50.11 <2e-16 ***
IMC3 2.644e+01 2.737e-01 96.59 <2e-16 ***
IMC4 4.368e+01 2.818e-01 154.99 <2e-16 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 5.747 on 21993 degrees of freedom
Multiple R-squared: 0.8514, Adjusted R-squared: 0.8514
F-statistic: 2.521e+04 on 5 and 21993 DF, p-value: < 2.2e-16# Sin IMC
lm3 <- lm(Peso ~ EDAD + Altura, salud)
summary(lm3)
Call:
lm(formula = Peso ~ EDAD + Altura, data = salud)
Residuals:
Min 1Q Median 3Q Max
-44.184 -8.402 -1.695 6.465 101.080
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) -87.869119 1.660849 -52.91 <2e-16 ***
EDAD 0.171006 0.004753 35.98 <2e-16 ***
Altura 0.908802 0.009384 96.85 <2e-16 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 12.47 on 21996 degrees of freedom
Multiple R-squared: 0.2999, Adjusted R-squared: 0.2998
F-statistic: 4711 on 2 and 21996 DF, p-value: < 2.2e-16Vemos que el Sexo no parece tener mucha importancia, no así el IMC que cuando lo sustraemos del modelo experimenta una bajada grande de bondad. Sin embargo al sustraer la variable IMC, vemos que el Adjusted R-squared baja bastante, por lo que se puede decir que dicha variable es de gran relevancia. Conceptualmente el IMC=peso/altura, y aunque nosotros sólo tengamos 4 categorías de IMC (en vez de la variable continua), es directo ver que dicha variable nos va a servir como gran fuente de información para predecir el peso. De manera contraria, el Sexo de una persona no parece estar muy correlacionado con el peso, hay mujeres y hombres con sobrepeso y mujeres y hombres con pesos bajos. Con la altura cabría esperar una relación más directa puesto que conforme crecemos (nos hacemos más altos), vamos aumentando de peso.
Es por ello que nos vamos a quedar con el modelo lm1 o lm2. Vamos a interpretar ahora los parámetros del modelo 1:
summary(lm1)
Call:
lm(formula = Peso ~ EDAD + Altura + IMC + SEXO, data = salud)
Residuals:
Min 1Q Median 3Q Max
-16.946 -3.845 -0.137 3.510 79.105
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) -94.986808 1.027145 -92.477 <2e-16 ***
EDAD 0.027838 0.002288 12.169 <2e-16 ***
Altura 0.854409 0.005848 146.115 <2e-16 ***
IMC2 13.430315 0.270893 49.578 <2e-16 ***
IMC3 26.165755 0.274741 95.238 <2e-16 ***
IMC4 43.391437 0.282888 153.387 <2e-16 ***
SEXO1 1.000631 0.106538 9.392 <2e-16 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 5.735 on 21992 degrees of freedom
Multiple R-squared: 0.852, Adjusted R-squared: 0.852
F-statistic: 2.11e+04 on 6 and 21992 DF, p-value: < 2.2e-16Vemos los siguientes coeficientes:
\(\beta (EDAD)\): tiene un valor muy bajo (0.02), siendo positivo. Esto indica que no parece tener mucho peso en el modelo y que conforme aumente la edad, aumenta el Peso de la persona muy ligeramente, lo cual podría parecer razonable.
\(\beta (Altura)\): tiene un valor de (0.85), siendo positivo. Parece razonable que sea mayor que el del beta relativo a la edad puesto que a más altura, más posibilidad de tener mas masa y por tanto más peso. De ahí que además sea positivo. Por cada unidad más de altura (cada cm), aumenta el peso en 0.85kg en media.
Destacar que ahora los siguientes betas se refieren a la variable IMC que es categórica. Es por ello que se toma como referencia la primera categoría (IMC=1) y los coeficientes representan el cambio de pasar de una categoría a otra.
\(\beta (IMC2)\): tiene un valor bastante alto (13.42), siendo positivo. Esto indica que al pasar de la clase IMC=1 (nivel base) A IMC=2, el peso aumenta en 13.42 puntos. Esto parece muy razonable puesto que en IMC=1 se representaba la gente con peso insuficiente y en IMC=2 la gente con peso normal. Es decir, el modelo nos está indicando que la diferencia entre ambas clases es de 13.42 kg.
\(\beta (IMC3)\): tiene un valor bastante alto (26), siendo positivo. Esto indica que al pasar de la clase IMC=1 A IMC=3, el peso aumenta en 13.42 puntos. Esto parece muy razonable puesto que en IMC=1 se representaba la gente con peso insuficiente y en IMC=3 la gente con sobrepeso. Además también es más grande que el beta anterior, indicando que es mas grande el cambio de peso entre gente con peso insuficiente y sobrepeso que entre las personas con peso insuficiente y peso normal.
\(\beta (IMC4)\): tiene un valor bastante alto (43), siendo positivo. Esto indica que al pasar de la clase IMC=1 A IMC=4, el peso aumenta en 13.42 puntos. Esto parece muy razonable puesto que en IMC=1 se representaba la gente con peso insuficiente y en IMC=4 la gente con obesidad. Además también es más grande que los betas anteriores, i indicando que es mas grande el cambio de peso entre gente con peso insuficiente y obesidad que entre el resto de clases.
\(\beta (SEXO1)\): tiene un valor igual a 1 (+1), siendo positivo. Puesto que es una variable factor, esto indica que pasar de la categoría base, mujer, a hombre, aumenta el peso. Esto también podría ser razonable puesto que manteniendo el resto de variables constantes, los hombres suelen tender ser más altos que las mujeres y por tanto tienden a pesar más. Es verdad que como hemos comentado antes, no es una correlación a prior tan evidente.
Predicción
Una vez que hemos seleccionado un modelo, en este caso lm1, vamos a predecir nuevas observaciones y calcular intervalos de confianza para estas. Utilizaremos los datos almacenados en IMCV_test. Para predecir usaremos la función predict(), que además nos puede proporcionar un intervalo de confianza para los valores predichos.
Para evaluar las predicciones vamos calcular:
Mean Absolute Error (MAE), que se calcula como la diferencia absoluta promedio entre los valores ajustados por el modelo (un paso por delante de la previsión de muestra) y los datos históricos observados. Representa cuanto esperamos desviarnos en una predicción. En este caso 3.78 puntos, lo cual es bastante preciso puesto que en personas con edades adultas 3kg arriba, 3kg abajo no es mucha diferencia.
Mean Absolute Percentage Error (MAPE), que se calcula como el promedio de las diferencias absolutas entre los valores pronosticados y los valores reales, expresadas como un porcentaje de los valores reales. Representa el error promedio absoluto de las predicciones del modelo, expresado como un porcentaje de los valores reales. En otras palabras, mide la magnitud relativa del error de las predicciones en comparación con los valores reales, permitiendo así una evaluación de la precisión del modelo de pronóstico.
En este caso es un 5%, luego no es una desviación muy grande de peso, y por ello se podría decir que el modelo es bueno prediciendo nuevas observaciones.
prediccion <- predict(lm1, salud_test[, c(1, 3, 5, 2)], interval = "confidence", level = 0.95)
valor_real <- salud_test[, 4]
# Calculamos el MAE
MAE <- sum(abs(prediccion[, 1] - valor_real)) / 20
MAPE <- sum(abs((prediccion[, 1] - valor_real) / valor_real)) * 100 / 20
paste0("El MAE es: ", round(MAE, 5))[1] "El MAE es: 3.78706"paste0("El MAPE es de: ", round(MAPE, 5), "%")[1] "El MAPE es de: 5.96217%"Vemos un MAE bastante bajo luego vemos que el modelo es bueno para predecir observaciones futuras, que no hay un sobre entrenamiento.
Conclusión
El modelo inicial considerado tiene buenos indicadores de bondad de ajuste. Además interpretando los resultados parece razonable todos los coeficientes e indicadores obtenidos.