library(readxl) # Para leer los excels
library(kableExtra) # Para dar formato a las tablas html
library(knitr) # Formato tablas en html
library(gridExtra) # Para el layout de los gráficos
library(car) # Para el bonfferroni test
library(corrplot) # Para el gráfico de correlaciones
library(ggplot2)
library(lmtest) # Test HomocedasticidadRegresión Lineal: IMCV_reg
Introducción
En este notebook se expondrá como llevar a cabo una Regresión Lineal a partir de un conjunto de datos, explicando las hipótesis que se deben satisfacer y un posterior análisis de bondad del modelo. Por último se explicará como utilizar el modelo creado para predecir nuevas observaciones.
Nota: Se trata de un ejemplo meramente didáctico ya que como se verá no tiene utilidad práctica puesto que se ha suprimido una dimensión.
dataset
El dataset imcv_reg.xlsx dispone de datos por Comunidades Autónomas de las nueve dimensiones relativas a la calidad de vida que componen el Índice Multidimensional de Calidad de Vida (IMCV) ¡Pincha aquí!, una estadística con carácter experimental. Datos correspondientes al año 2020.
Concretamente tenemos las siguientes variables:
- índice_total: Índice multidimensional de calidad de vida teniendo en cuenta las nueve dimensiones.
- dim1 : Indicador sobre las condiciones materiales de vida.
- dim2 : Indicador sobre el trabajo.
- dim3 : Indicador sobre la salud.
- dim4 : Indicador sobre la educación.
- dim5 : Indicador sobre el ocio y relaciones sociales.
- dim6 : Indicador sobre la seguridad física y personal.
- dim7 : Indicador sobre la gobernanza y los derechos básicos.
- dim8 : Indicador sobre el entorno y el medioambiente.
- CCAA: Comunidades Autónomas.
Los datos relativos a este estudio corresponden, como ya se ha comentado, a la estadística experimental sobre el ÍndiceMultidimensional de Calidad de Vida (IMCV). Se construye a partir de los indicadores de calidad del INE, que ofrecen una visión panorámica (multidimensional) de la calidad de vida en España, mediante la elección de un conjunto amplio pero limitado de indicadores (actualmente 60) que cubren nueve dimensiones usadas para describir la calidad de vida.
Nota: Notar que en este dataset no se tiene la variable dim9 ya que en ese caso el ajuste de la regresión sería prefecto puesto que la variable índice_total es la media aritmética de las 9 dimensiones.
Descripción del trabajo a realizar
Elaborar una Regresión Lineal que explique el índice total en función de las dimensiones (sin tener en cuenta la variable CCAA que tiene mero sentido identificador de las observaciones). Pasos recomendados:
- Hacer un análisis exploratorio.
- Plantear las hipótesis de una regresión (incluyendo todas variables).
- Analizar el modelo planteado y su ajuste de bondad.
- Evaluar distintos modelos y seleccionar el más adecuado.
- Conclusión.
Análisis Exploratorio (EDA)
EDA viene del Inglés Exploratory Data Analysis y son los pasos relativos en los que se exploran las variables para tener una idea de que forma toma el dataset.
Cargar Librerías
Lo primero de todo vamos a cargar las librerías necesarias para ejecutar el resto del código del trabajo:
Lectura datos
Ahora cargamos los datos del excel correspondientes a la pestaña “Datos” y vemos si hay algún NA o algún valor igual a 0 en nuestro dataset. Vemos que no han ningún NA (missing value) en el dataset luego no será necesario realizar ninguna técnica para imputar los missing values o borrar observaciones.
IMCV <- read_excel("../../../files/IMCV_reg.xlsx", sheet = "Datos")c(
anyNA(IMCV), # Any missing data
any(IMCV == 0)
) # Any value equal to 0[1] FALSE FALSEAnálisis
Realizando un resumen numérico vemos que todas las dimensiones toman valores en torno a \([90,110]\). Recordar que estas representan índices. Para ninguna de ellas parece haber valores atípicos en relación a los demás luego no parece necesario hacer ningún tipo de ajuste a los datos.
Además las medias y medianas son muy parecidas. Junto con los histogramas y los boxplots se podría concluir que no parece haber ningún dato atípico/outlier y tampoco parece haber mucha asimetría, hecho que se puede ver en los histogramas y en los boxplots (mirando las distancias entre máximo/tercer cuartil y mínimo/1er cuartil son parecidas).
| variable | Min | Q1 | Mean | Median | Q3 | Max | |
|---|---|---|---|---|---|---|---|
| año | año | 2020.00 | 2020.00 | 2020.50 | 2020.50 | 2021.00 | 2021.00 |
| dim1 | dim1 | 90.99 | 97.41 | 100.04 | 100.64 | 103.46 | 105.35 |
| dim2 | dim2 | 94.47 | 97.59 | 99.69 | 99.92 | 102.57 | 103.42 |
| dim3 | dim3 | 98.20 | 99.69 | 101.14 | 100.80 | 102.32 | 105.49 |
| dim4 | dim4 | 97.35 | 103.97 | 107.33 | 106.94 | 109.58 | 118.46 |
| dim5 | dim5 | 94.32 | 96.69 | 99.75 | 99.48 | 102.05 | 107.28 |
| dim6 | dim6 | 92.89 | 99.81 | 102.83 | 102.76 | 106.39 | 109.48 |
| dim7 | dim7 | 91.22 | 96.36 | 99.97 | 100.23 | 102.73 | 109.35 |
| dim8 | dim8 | 93.17 | 98.93 | 102.51 | 103.99 | 105.88 | 109.42 |
| indice_total | indice_total | 96.05 | 100.33 | 101.80 | 102.07 | 103.61 | 105.87 |
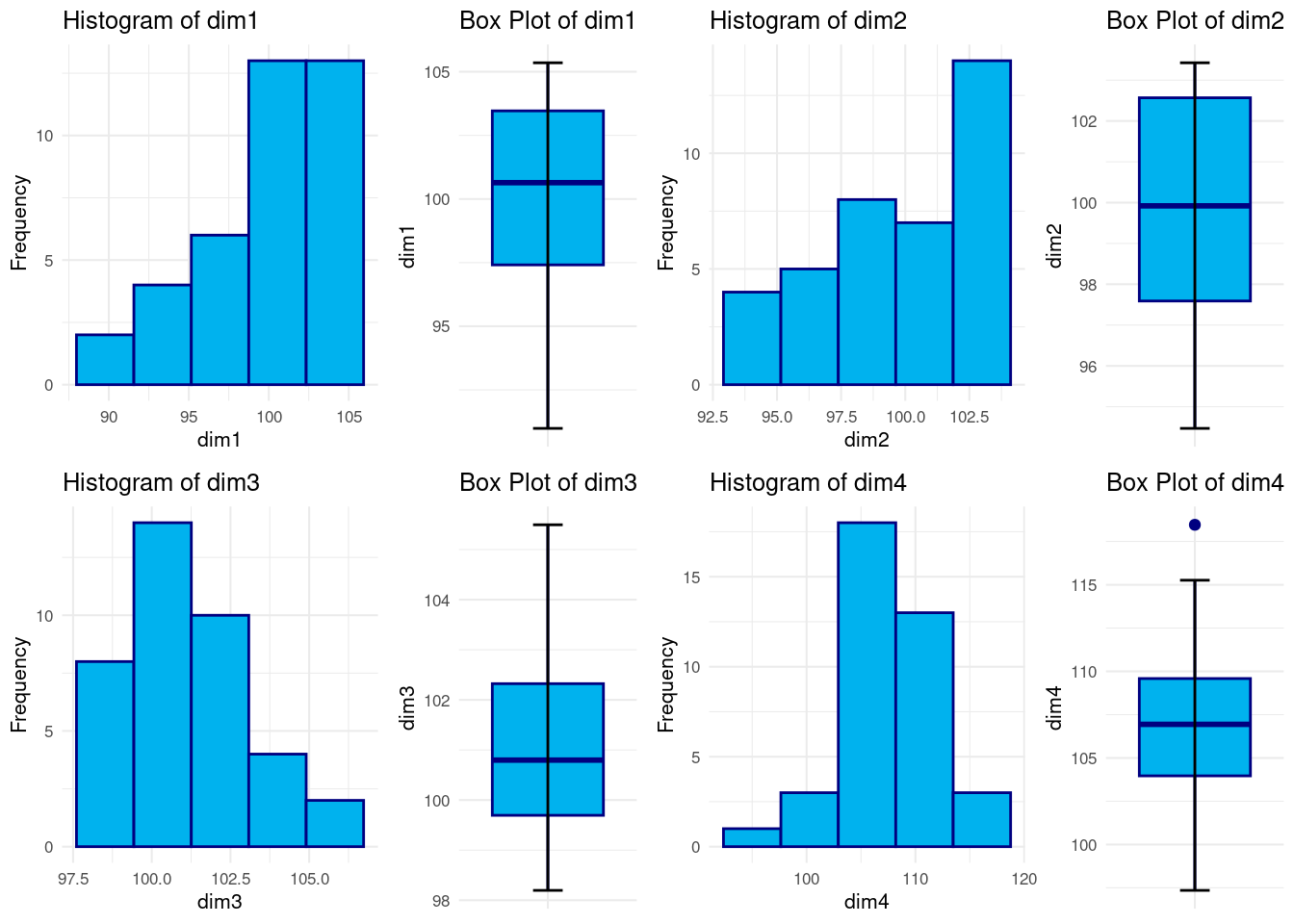
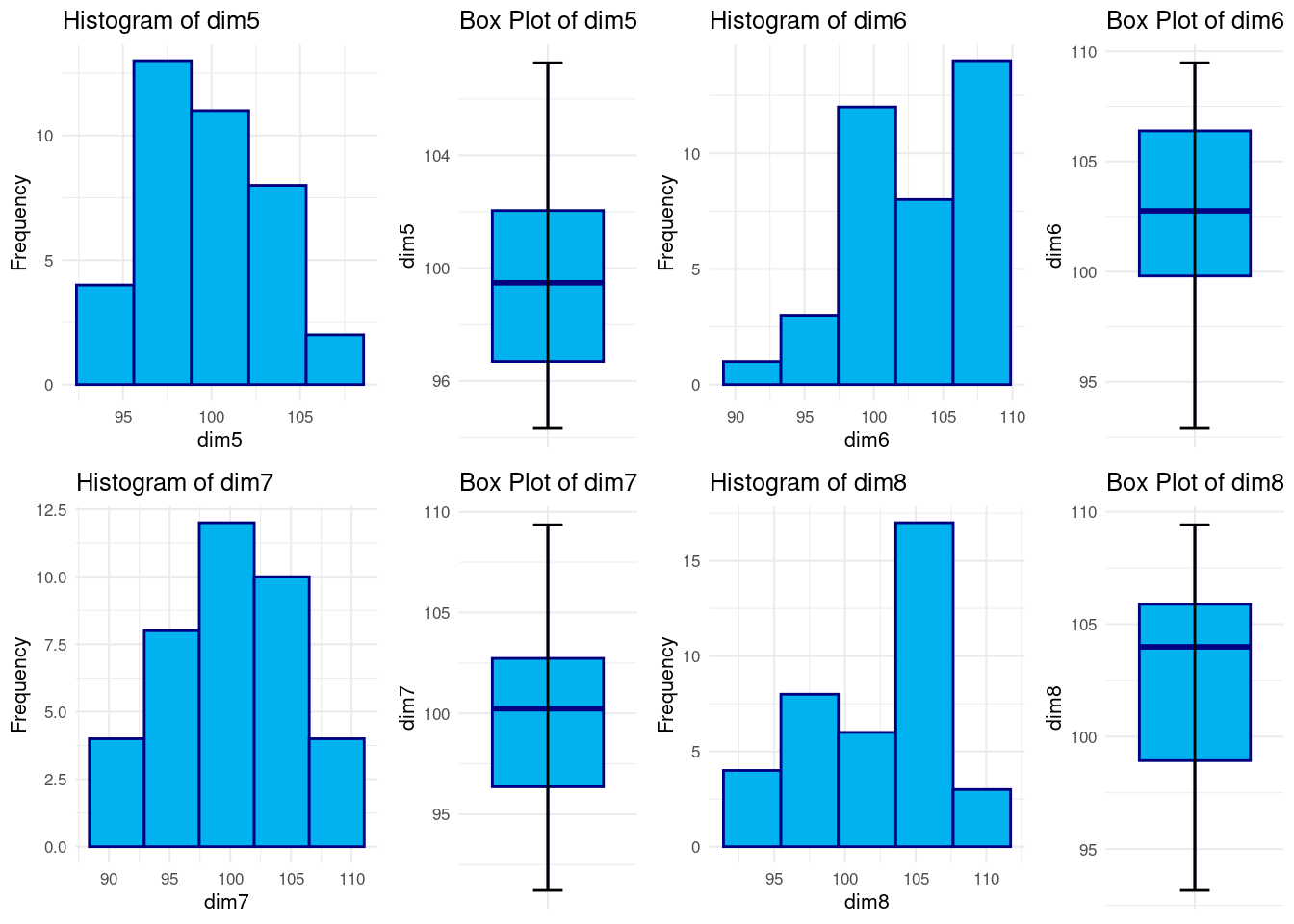
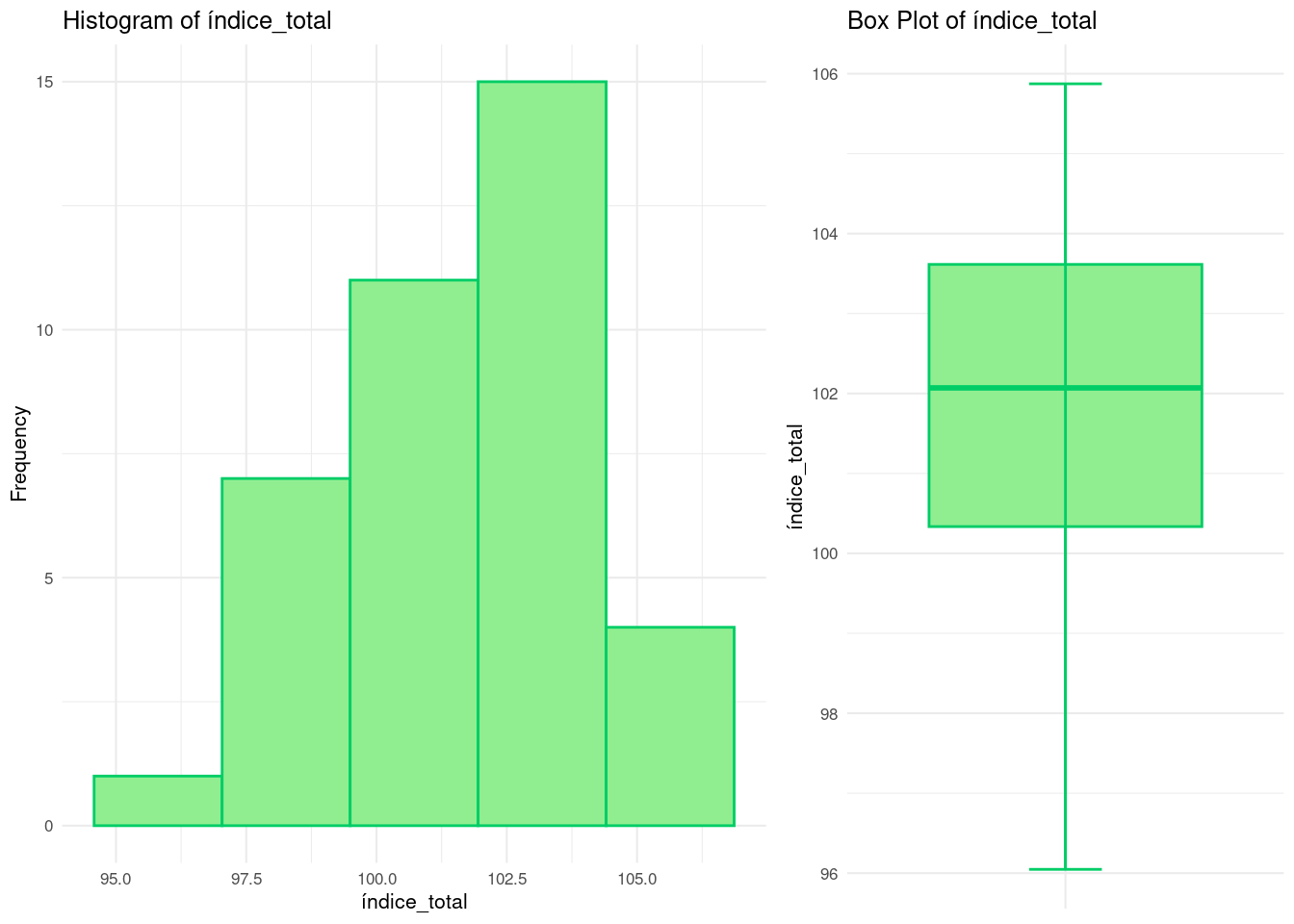
En general parecen unos datos bien balanceados y con buenas propiedades.
Regresión Lineal
Una Regresión Lineal es una técnica estadística que busca ajustar un conjunto de datos a una recta. Es decir, dada una observación x, se proyecta sobre la recta y se obtiene un valor y, de tal manera que si el ajuste por regresión es bueno entonces la \(\hat{y}\) obtenida se parece mucho al valor real \(y\).
Antes de explicar las hipótesis que deben cumplir los datos para que el ajuste y como llevarlo a cabo, se va a mostrar un ejemplo de buen y mal ajuste. Intuitivamente cuanto mejor sea el ajuste de los datos a una recta cuando se representen las observaciones en un gráfico, mejor será el ajuste.
par(mfrow = c(1, 2)) # Dos gráficos misma fila
# Poca variabilidad
x <- seq(1, 100, 1)
y <- rnorm(100, x, 5)
p1 <- plot(y, col = "lightblue", main = "BUENO Ajuste") + abline(lm(y ~ x), col = "navy")
# Mucha variabilidad
x_malo <- seq(1, 100, 1)
y_malo <- rnorm(100, x, 35)
p2 <- plot(y_malo, col = "lightblue", main = "MAL Ajuste") + abline(lm(y_malo ~ x_malo), col = "navy")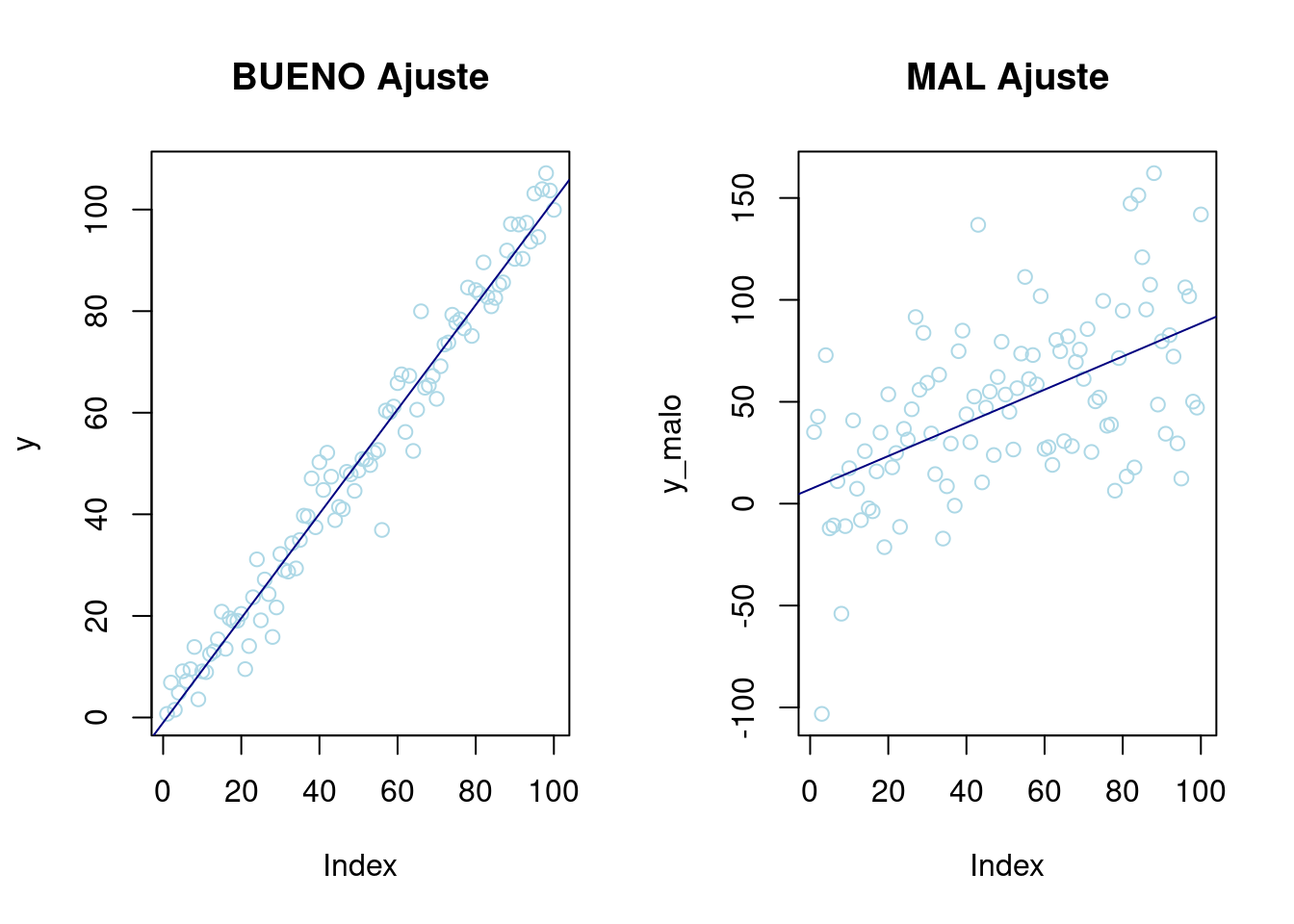
Hipótesis y indicadores de bondad
Para que una regresión lineal proporcione un buen ajuste a los datos debe cumplir una serie de requisitos que por tanto deben ser verificados al llevar a cabo el estudio. Recordar que la regresión lineal se expresa como: \[ \mathbf{Y}=\mathbf{X} \boldsymbol{\beta}+\boldsymbol{\varepsilon} \] donde \(\mathbf{Y}\) es la variable respuesta, \(\mathbf{X}\) los predictores (hay \(k\) variables predictoras), \(\boldsymbol{\beta}\) los coeficientes de la regresión y \(\boldsymbol{\varepsilon}\) el error. \[ \mathbf{Y}=\left[\begin{array}{c} y_1 \\ y_2 \\ \vdots \\ y_n \end{array}\right] \quad \mathbf{X}=\left[\begin{array}{cccc} 1 & x_{11} & \ldots & x_{1 k} \\ 1 & x_{21} & \ldots & x_{2 k} \\ \vdots & \ddots & \vdots & \\ 1 & x_{n 1} & \ldots & x_{n k} \end{array}\right] \quad \boldsymbol{\beta}=\left[\begin{array}{c} \beta_0 \\ \beta_1 \\ \vdots \\ \beta_k \end{array}\right] \quad \boldsymbol{\varepsilon}=\left[\begin{array}{c} \varepsilon_1 \\ \varepsilon_2 \\ \vdots \\ \varepsilon_n \end{array}\right] \] Las hipótesis que se deben cumplir son:
Linealidad: La media de la respuesta es función lineal de los predictores. En términos matemáticos: \[E\left[\mathbf{Y} \mid \mathbf{X}_1=x_1, \ldots, \mathbf{X}_k=x_k\right]=\beta_0+\beta_1 x_1+\ldots+\beta_k x_k \]
Independencia de errores: Los errores \(\varepsilon_i\) deben ser independientes, es decir, \(Cov[\varepsilon_i,\varepsilon_j] =0, \; \forall i\neq j\).
Homocedasticidad: La varianza del error debe ser constante.
\[Var\left[\varepsilon_i \mid \mathbf{X}_1=x_1, \ldots, \mathbf{X}_k=x_k\right]=\sigma^2 \quad \forall \;i \]
- Normalidad : Los errores deben estar distribuidos normalmente, es decir, \(\varepsilon_i \sim N(0,\sigma^2)\; \forall i\).
Para analizar la bondad, hay algunos indicadores como el Coeficiente de Determinación o \(R^2\) que representa el porcentaje de variabilidad de la variable respuesta que es capaz de explicar el modelo. Es decir, si toma valor 1 hay una dependencia lineal exacta entre los predictores y la variable respuesta y por tanto las predicciones serán perfectas. Por el contrario, si toma valor 0 habrá que desechar el modelo puesto que no es capaz de predecir con nada de exactitud.
En caso de que haya más de un predictor (\(k >1\), Regresión Lineal Múltiple), es más recomendable usar el Coeficiente de Determinación Ajustado \(R^2\_adj\) como indicador de bondad, pues el \(R^2\) puede inflarse artificialmente debido a la presencia de varios predictores. Su interpretación es similar.
Modelo
En este caso nos encontramos ante una Regresión Lineal Múltiple puesto que tenemos más de una variable predictora. Inicialmente vamos a considerar un modelo con todas variables predictoras para intentar predecir el \(índice\_total\) y veremos si este modelo cumple las hipótesis necesarias y cuan bueno es.
Este modelo busca ajustar el índice_total en función de las 8 primeras dimensiones.
IMCV_test <- IMCV[35:38, ] # Guardamos parte de los datos para evaluar después
IMCV <- IMCV[1:34, ]
# Modelo inicial
lm1 <- lm(indice_total ~ dim1 + dim2 + dim3 + dim4 + dim5 + dim6 + dim7 + dim8, IMCV)
summary(lm1)
Call:
lm(formula = indice_total ~ dim1 + dim2 + dim3 + dim4 + dim5 +
dim6 + dim7 + dim8, data = IMCV)
Residuals:
Min 1Q Median 3Q Max
-0.58365 -0.12689 -0.02845 0.16057 0.55151
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 4.85420 4.38109 1.108 0.27841
dim1 0.09629 0.04879 1.973 0.05961 .
dim2 0.09238 0.04681 1.973 0.05960 .
dim3 0.05916 0.05847 1.012 0.32136
dim4 0.15649 0.02109 7.419 9.04e-08 ***
dim5 0.13516 0.02317 5.833 4.40e-06 ***
dim6 0.08815 0.02989 2.949 0.00682 **
dim7 0.14988 0.01256 11.935 8.07e-12 ***
dim8 0.17320 0.03310 5.233 2.04e-05 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 0.2995 on 25 degrees of freedom
Multiple R-squared: 0.9874, Adjusted R-squared: 0.9834
F-statistic: 245.3 on 8 and 25 DF, p-value: < 2.2e-16A primera vista vemos un valor de Múltiple R-squared: 0.9812,, lo cual es bastante alto y por tanto nuestro modelo parece capturar bien la variabilidad de la variable respuesta, concretamente un \(98\%\). Sin embargo, en los sucesivos modelos que planteemos no podemos usar como criterio de comparación el \(R-squared\) pues aumenta a la vez que lo hace el número de variables, y por tanto para comparar modelos entre si se debe usar el Adjusted R-squared (que tiene en cuenta el número de variables).
En la línea de los residuos no parece haber contraindicaciones a que estos sigan una distribución normal centrada en cero puesto que tenemos unas medidas de dispersión bastante simétricas. No obstante, más adelante se procederán a hacer los test pertinentes.
En la última linea se lleva a cabo un Test de Significación Global \(F-Test\) lo que considera es la hipótesis nula de
\[H_0: \beta_i =0\; \forall i \\ H_1: al\; menos \; un \; \beta_i \neq 0\].
Para un nivel de confianza de \(0.95\) podemos rechazar la hipótesis nula (puesto que p_val< 0.05) y por tanto aceptar la alternativa, lo cual es buena señal.
No obstante es necesario analizar que se cumplan las hipótesis iniciales para poder asegurar que estamos ante un buen modelo.
Test de Bonferroni (datos atípicos)
La idea principal es verificar si los residuos de las observaciones son significativamente diferentes de cero. Si un residuo tiene un valor “studentizado” grande en comparación con una distribución t, puede considerarse como un posible valor atípico. Esto se debe a que teóricamente se demuestra que los residuos “studentizados” \(r^* _i \sim t_{n-k-1}\) con k el número de predictores. En este caso parece no haber indicación de valores atípicos.
outlierTest(lm1)No Studentized residuals with Bonferroni p < 0.05
Largest |rstudent|:
rstudent unadjusted p-value Bonferroni p
31 -2.511136 0.019173 0.65187Test homocedasticidad
En términos sencillos, la Prueba de Breusch-Pagan evalúa si la varianza de los errores en un modelo de regresión es constante o si varía a lo largo de los valores de las variables predictoras. Una violación de la homocedasticidad puede afectar la validez de las inferencias realizadas a partir del modelo.
El test funciona de la siguiente manera: se obtienen los residuos al cuadrado y se realiza una regresión auxiliar para determinar si hay una relación significativa entre los residuos al cuadrado y las variables predictoras. Si se encuentra evidencia significativa, puede indicar la presencia de heterocedasticidad.
bptest(indice_total ~ dim1 + dim2 + dim3 + dim4 + dim5 + dim6 + dim7 + dim8, data = IMCV, varformula = ~ fitted.values(lm1), studentize = FALSE)
Breusch-Pagan test
data: indice_total ~ dim1 + dim2 + dim3 + dim4 + dim5 + dim6 + dim7 + dim8
BP = 0.93094, df = 1, p-value = 0.3346\[H_0: Var[\varepsilon_i ] =\sigma^2 \; \forall \;i \\ H_1: Var[\varepsilon_i ] \neq \sigma^2 \; \forall \;i\].
Si el valor p obtenido de la prueba de Breusch-Pagan es \(0.33\), interpretaríamos esto como evidencia insuficiente para rechazar la hipótesis nula de homocedasticidad (a nivel de significancia de \(0.05\)). En otras palabras, no tendríamos suficiente evidencia estadística para decir que hay heterocedasticidad en los errores del modelo de regresión.
En términos prácticos, esto sugiere que la varianza de los errores parece ser constante a lo largo de los valores de las variables predictoras.
Normalidad de residuos
El Test de Shapiro es una prueba de normalidad que se utiliza para evaluar si una muestra proviene de una población con una distribución normal. La hipótesis nula del test es que la muestra sigue una distribución normal. Si el valor p obtenido en la prueba es menor que el nivel de significancia (comúnmente establecido en \(0.05\)), se rechaza la hipótesis nula, indicando que la muestra no sigue una distribución normal.
\[H_0: \varepsilon_i \sim N(\;,\;) \; \forall \\ H_1: \varepsilon_i \nsim N(\;,\;) \; \forall \].
shapiro.test(lm1$residuals)
Shapiro-Wilk normality test
data: lm1$residuals
W = 0.98163, p-value = 0.8226Aceptamos la normalidad de los residuos puesto que el \(p-value>0.05\).
Test linealidad
La hipótesis alternativa analiza si la inclusión de términos cuadráticos (potencia 2) de las variables predictoras mejora significativamente el modelo en comparación con un modelo que solo incluye términos lineales.
resettest(indice_total ~ dim1 + dim2 + dim3 + dim4 + dim5 + dim6 + dim7 + dim8, data = IMCV, power = 2, type = "regressor")
RESET test
data: indice_total ~ dim1 + dim2 + dim3 + dim4 + dim5 + dim6 + dim7 + dim8
RESET = 1.7105, df1 = 8, df2 = 17, p-value = 0.1675Aceptamos la linealidad puesto que el \(p-value>0.05\), a un nivel de significancia de \(\alpha =0.05\), luego no es necesario incluir términos cuadráticos.
Gráfico de influencia del modelo porpuesto
En el siguiente gráfico se muestran los residuos “studentizados”, es decir, los residuos transformados a una \(N(0,1)\). Es por ello, que debido a el cuantil \(z_{\alpha/2}=-1.96\; con \; \alpha=0.05\) de una normal, sabemos que el \(95\%\) de elementos deben estar contenidos en \((-1,96,1.96)\) que son las rayas horizontales del gráfico.
influencePlot(lm1, id = list(method = "noteworth", n = 2))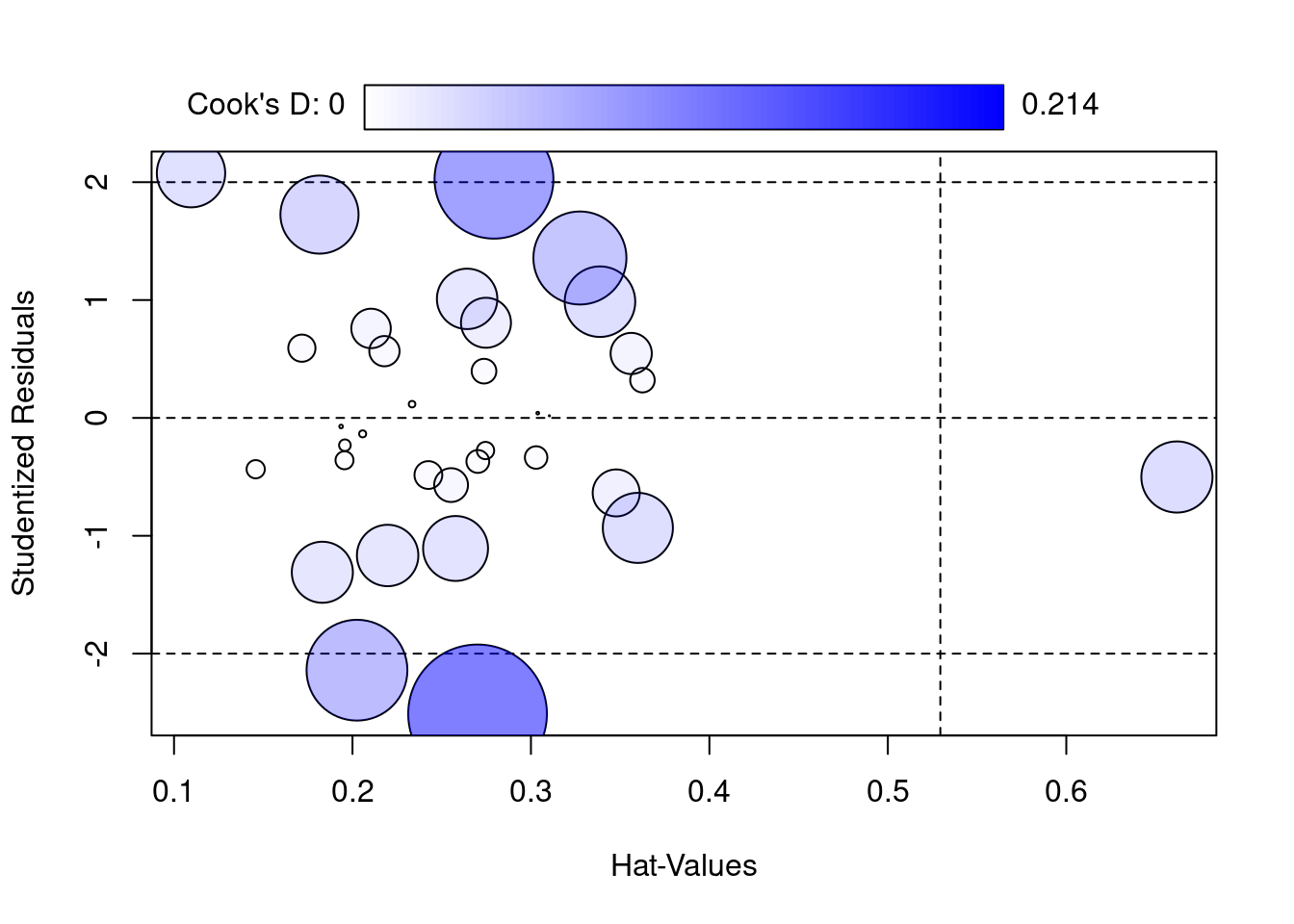
- Los residuos bajo hipótesis de RLM siguen una N(0,sigma) y los “studentizados” un N(0,1), es decir el \(95\%\) de datos están entre \((-1.96,1.96)\), las líneas horizontales. Tenemos 20 observaciones y 2 datos fuera de la línea lo que a priori podría ser correcto.
- Las líneas verticales indican los datos con apalancamiento en el modelo. Es decir los datos fuera de la línea vertical derecha No vemos ni siquiera las lineas entonces no parece haber apalancamiento.
- El área de las burbujas es proporcional a la Distancia de Cook (mide cómo cambian los parámetros del modelo cuando se excluye una observación específica). Vemos que hay uno con una gran distancia de cook (tienen residuo grande), luego esto nos indica que podría considerarse en cierto modo atípico. Como no hemos encontrado más evidencias de que fuera atípico lo vamos a dejar así.
Colinealidad
Cuando los regresores no tienen una relación lineal, se consideran ortogonales. Sin embargo, en la mayoría de las aplicaciones de regresión, los regresores no cumplen con esta condición. En algunos casos, la falta de ortogonalidad no representa un problema significativo, pero en otros, los regresores pueden estar tan estrechamente relacionados linealmente de manera que las predicciones del modelo de regresión se vuelven poco fiables o incorrectas.
Este fenómeno, en el que los regresores presentan dependencias lineales casi perfectas, se conoce como el problema de colinealidad. Se realiza la matriz de correlaciones para ver la dependencia lineal entre las distintas variables.
mat_cor <- cor(IMCV[, 2:10]) %>% round(digits = 2)
corrplot(mat_cor, type = "upper", order = "hclust", tl.col = "black", tl.srt = 45)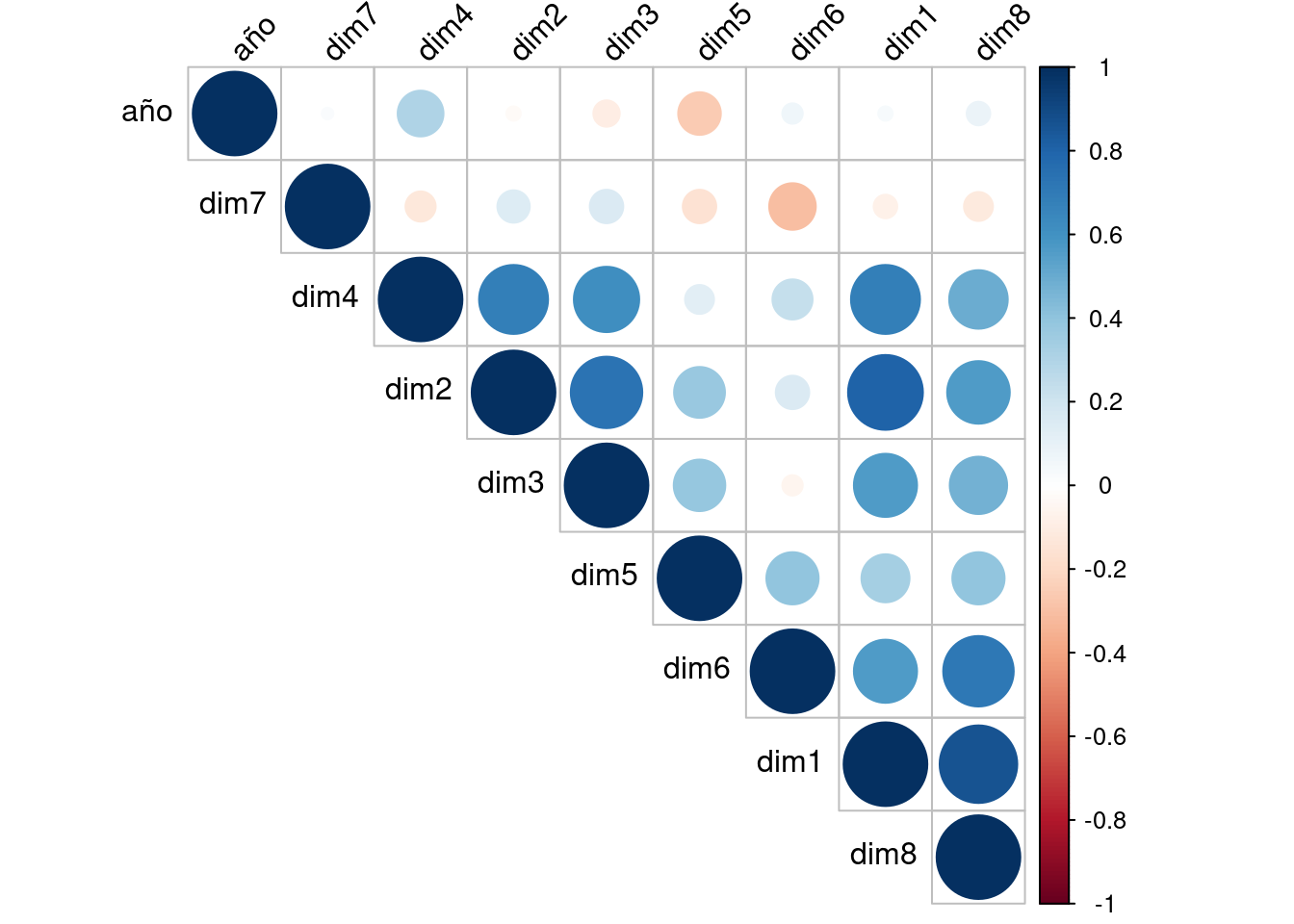
Combinando los resultados de la matriz anterior y el conocimiento de las variables es posible identificar variables que podrían generar el problema de multicolinealidad. De hecho si en el conjunto de datos hubiéramos tenido todas las dimensiones (de la 1 a la 9) y índice_total, hubiera habido un problema de colinealidad puesto que el índice total es la media aritmética del resto de dimensiones. Es por ello que se ha optado por suprimir la última dimensión.
Por otro lado, el factor de inflación de la varianza (FIV) detecta si una variable independiente es colineal con el resto. Es decir, mira cuanto se infla la varianza de los estimadores por culpa de la colinealidad de unas variables respecto a otras. Decisión: Un Valor del FIV mayor de 10 requiere actuación.
# Inflación de la varianza
vif(lm1) dim1 dim2 dim3 dim4 dim5 dim6 dim7 dim8
12.814957 7.087505 4.764287 3.043847 2.324441 5.740449 1.424524 7.781270 Vemos que la primera dimensión podría presentar problemas de colinealidad.
Selección de Modelos
A la hora de realizar un modelo de acuerdo a una lista de variables estadísticas, suele ser frecuente estudiar la relevancia de todas ellas, o si por el contrario con un número reducido de predictores es suficiente. Además del \(R^2_{adj}\), el Criterio de Información de Akaike (AIC), es una medida para comparar diferentes modelos. Comparando dos modelos, el que tenga un AIC más bajo se puede considerar mejor modelo.
Vamos a realizar un método de Stepwise que lo que hace es incluyendo/sacando variables sobre el modelo inicial hasta encontrar el modelo con el mejor AIC(el más bajo). Es una forma de encontrar el modelo con el menor número de variables y las mejores métricas. No se ejecuta en el notebook dicha función puesto que tiene una salida muy larga, aunque es recomendable su uso.
library(Rcmdr)
stepwise(lm1, direction = "backward/forward", criterion = "AIC")Destacar que la realidad es que:
\[indice\_ total = dim1+dim2+dim3+dim4+dim5+dim6+dim7+dim8+dim9\]. En este caso no disponemos de \(dim9\). No obstante parece obvio que la mejor estimación se da usando todas las variables, incluso aun habiendo indicios de no hacerlo.
Predicción
Una vez que hemos seleccionado un modelo, en este caso lm1, vamos a predecir nuevas observaciones y calcular intervalos de confianza para estas. Utilizaremos los datos almacenados en IMCV_test. Para predecir usaremos la función predict(), que además nos puede proporcionar un intervalo de confianza para los valores predichos.
Posteriormente vamos a calcular el Mean Absolute Error (MAE), que se calcula como la diferencia absoluta promedio entre los valores ajustados por el modelo (un paso por delante de la previsión de muestra) y los datos históricos observados.
prediccion <- predict(lm1, IMCV_test[, 3:10], interval = "confidence", level = 0.95)
valor_real <- IMCV_test[, 11]
# Calculamos el MAE
MAE <- sum(abs(prediccion[, 1] - valor_real)) / 11
MAE[1] 0.157824Vemos un MAE bastante bajo luego vemos que el modelo es bueno para predecir observaciones futuras, que no hay un sobre entrenamiento.
Conclusion
El modelo inicial considerado tiene buenos indicadores de bondad de ajuste y además pasa las hipótesis requeridas para una regresión lineal. Es por ello que parece razonable tomarlo como bueno y usarlo para predecir observaciones futuras.